前言
80 多年来,人们一直在为电子计算机编写程序,但令人惊讶的是,关于如何设计这些程序或什么是好的程序应该是什么样子的讨论却很少。关于软件开发过程(如敏捷开发)和开发工具(如调试器、版本控制系统和测试覆盖工具),已经有了相当多的讨论。还广泛分析了编程技术,如面向对象编程和函数式编程,以及设计模式和算法。所有这些讨论都是有价值的,但是软件设计的核心问题在很大程度上仍然没有触及。David Parnas 的经典论文“关于将系统分解成模块的标准”发表于 1971 年,但是在随后的 45 年里,软件设计的技术水平并没有超过这篇论文。
计算机科学中最基本的问题是问题分解:如何处理复杂的问题并将其分解为可以独立解决的部分。问题分解是程序员每天都要面对的中心设计任务,但是,除了这里描述的工作之外,我还没有在任何一所大学里找到一门以问题分解为中心的课程。我们讲授循环和面向对象的程序设计,而不是软件设计。
此外,程序员之间在质量和生产率上存在巨大差异,但是我们几乎没有尝试去了解什么使最好的程序员变得更好,或者在我们的课堂上教授这些技能。我曾与几位我认为是优秀的程序员的人进行过交谈,但是他们中的大多数人都难以阐明赋予他们优势的特定技术。许多人认为软件设计技能是天生的天赋,无法教授。但是,有相当多的科学证据表明,许多领域的杰出表现更多地与高质量的实践有关,而不是与先天能力有关(例如,参见 Geoff Colvin 的《人才被高估》)。
多年来,这些问题使我感到困惑和沮丧。我想知道是否可以教授软件设计,并且我假设设计技巧是区分优秀程序员和普通程序员的原因。我最终决定,回答这些问题的唯一方法是尝试教授软件设计课程。结果是斯坦福大学的 CS 190。在这一节课中,我提出了一套软件设计原则。然后,学生将通过一系列项目来吸收和实践这些原理。该课程的授课方式类似于传统的英语写作课。在英语课堂上,学生使用迭代过程,在其中编写草稿,获取反馈,然后重写以进行改进。在 CS 190 中,学生从头开始开发大量软件。然后,我们将进行大量的代码审查以识别设计问题,然后学生修订其项目以解决问题。这使学生可以了解如何通过应用设计原理来改进其代码。
现在,我已经教过 3 次软件设计课程,并且本书是基于该课程中出现的设计原理编写的。这些原则是相当高的水平,并且是哲学上的边界(“定义错误不再存在”),因此学生很难以抽象的方式理解这些思想。通过编写代码,犯错误,然后查看他们的错误以及后续的修正与这些原则之间的关系,学生将学得最好。
在这一点上,您可能会想知道:是什么让我认为我知道有关软件设计的所有答案?老实说,我没有。当我学会编程时,没有关于软件设计的课程,而且我从来没有导师来教我设计原理。在我学习编程时,几乎没有代码审查。我对软件设计的想法来自于编写和阅读代码的个人经验。在我的职业生涯中,我已经用多种语言编写了大约 250,000 行代码。我曾在团队中工作过,这些团队从零开始创建了三个操作系统,多个文件和存储系统,基础结构工具(例如调试器,构建系统和 GUI 工具包),脚本语言以及用于文本,图形,演示文稿和集成电路的交互式编辑器。一路上,我亲身经历了大型系统的问题,并尝试了各种设计技术。另外,我已经阅读了很多其他人编写的代码,这使我接触到了很多方法,无论是好是坏。
从所有这些经验中,我尝试提取通用线程,包括有关避免的错误和使用的技巧。本书反映了我的经验:这里描述的每个问题都是我亲身经历的,每种建议的技术都是我在自己的编码中成功使用的一种技术。
我不希望这本书成为软件设计的定论。我敢肯定,我错过了一些有价值的技术,从长远来看,我的一些建议可能会变成坏主意。但是,我希望本书能开始有关软件设计的对话。将本书中的想法与您自己的经验进行比较,并自己决定此处介绍的方法是否确实降低了软件复杂性。这本书是一个观点,所以有些读者会不同意我的一些建议。如果您不同意,请尝试理解原因。我有兴趣了解对您有用的东西,不起作用的东西以及您可能对软件设计有任何其他想法。我希望随后的对话将增进我们对软件设计的集体理解。
与我交流有关这本书的最好方法是将电子邮件发送到以下地址:
software-design-book@googlegroups.com
我有兴趣听取有关本书的特定反馈,例如错误或改进建议,以及与软件设计相关的一般思想和经验。我对可以在本书未来版本中使用的引人注目的示例特别感兴趣。最好的示例说明了重要的设计原理,并且足够简单,可以在一两个段落中进行解释。如果您想在电子邮件地址上看到其他人在说什么并参与讨论,可以加入 Google Group software-design-book。
如果出于某种原因该 software-design-book Google Group 将来会消失,请在 Web 上搜索我的主页;它将包含有关如何与这本书进行交流的更新说明。请不要将与图书相关的电子邮件发送到我的个人电子邮件地址。
我建议您使用本书建议时持保留态度。总体目标是降低复杂性;这比您在此处阅读的任何特定原理或想法更为重要。如果您尝试从本书中获得一个想法并发现它实际上并没有降低复杂性,那么您就不必继续使用它(但是,请让我知道您的经验;我想获得那些有效和无效建议的反馈)。
许多人提出了批评或提出建议,以提高本书的质量。以下人员对本书的各种草稿提供了有用的意见:杰夫·迪恩,桑杰·格玛瓦特,约翰·哈特曼,布莱恩·科尼根,詹姆斯·科佩尔,艾米·奥斯特豪特,凯·奥斯特豪特,罗伯·派克,帕塔·朗格纳森,基思·施瓦茨和亚历克斯·斯内普斯。Christos Kozyrakis 为类和接口建议了术语“深层”和“浅层”,代替了之前有点模糊的术语“厚”和“薄”。我很感激 CS 190 中的学生;阅读他们的代码并与他们讨论的过程有助于明确我对设计的想法。
第 1 章 介绍
编写计算机软件是人类历史上最纯粹的创作活动之一。程序员不受诸如物理定律等实际限制的约束。我们可以用现实世界中永远不会存在的行为创建令人兴奋的虚拟世界。编程不需要很高的身体技能或协调能力,例如芭蕾或篮球。所有编程都需要具有创造力的头脑和组织思想的能力。如果您能够将一个系统具象化,就可以在计算机程序中将它实现。
这意味着编写软件的最大限制是我们了解所创建系统的能力。随着程序的发展和获得更多功能,它变得复杂,其组件之间具有微妙的依赖性。随着时间的流逝,复杂性不断累积,程序员在修改系统时将所有相关因素牢记在心中变得越来越难。这会减慢开发速度并导致错误,从而进一步延缓开发速度并增加成本。在任何程序的生命周期中,复杂性都会不可避免地增加。程序越大,工作的人越多,管理复杂性就越困难。
好的开发工具可以帮助我们应对复杂性,并且在过去的几十年中已经创建了许多出色的工具。但是,仅凭工具我们只能做些事情。如果我们想简化编写软件的过程,从而可以更便宜地构建功能更强大的系统,则必须找到简化软件的方法。尽管我们尽了最大努力,但复杂度仍会随着时间的推移而增加,但是更简单的设计使我们能够在复杂性压倒性优势之前构建更大,功能更强大的系统。
有两种解决复杂性的通用方法,这两种方法都将在本书中进行讨论。第一种方法是通过使代码更简单和更明显来消除复杂性。例如,可以通过消除特殊情况或以一致的方式使用标识符来降低复杂性。
解决复杂性的第二种方法是封装它,以便程序员可以在系统上工作而不会立即暴露其所有复杂性。这种方法称为模块化设计。在模块化设计中,软件系统分为模块,例如面向对象语言的类。这些模块被设计为彼此相对独立(低耦合),以便程序员可以在一个模块上工作而不必了解其他模块的细节。
由于软件具有很好的延展性,因此软件设计是一个贯穿软件系统整个生命周期的连续过程。这使得软件设计与诸如建筑物,船舶或桥梁的物理系统的设计不同。但是,并非总是以这种方式查看软件设计。在编程的大部分历史中,设计都集中在项目的开始,就像其他工程学科一样。这种方法的极端称为瀑布模型,该模型将项目划分为离散的阶段,例如需求定义,设计,编码,测试和维护。在瀑布模型中,每个阶段都在下一阶段开始之前完成;在许多情况下,每个阶段都由不同的人负责。在设计阶段,立即设计整个系统。
不幸的是,瀑布模型很少适用于软件。软件系统本质上比物理系统复杂。在构建任何东西之前,不可能充分具象化出大型软件系统的设计,以了解其所有含义。结果,初始设计将有许多问题。在实施良好之前,问题不会变得明显。但是,瀑布模型的结构此时无法适应主要的设计更改(例如,设计师可能已转移到其他项目)。因此,开发人员尝试在不改变整体设计的情况下解决问题。这导致复杂性的爆炸式增长。
由于这些问题,当今大多数软件开发项目都使用诸如敏捷开发之类的增量方法,其中初始设计着重于整体功能的一小部分。设计,实施和评估此子集。发现和纠正原始设计的问题,然后设计,实施和评估更多功能。每次迭代都会暴露现有设计的问题,这些问题在设计下一组功能之前就已得到解决。通过以这种方式扩展设计,可以在系统仍然很小的情况下解决初始设计的问题。较新的功能受益于较早功能的实施过程中获得的经验,因此问题较少。
增量方法适用于软件,因为软件具有足够的延展性,可以在实施过程中进行重大的设计更改。相比之下,对物理系统而言,主要的设计更改更具挑战性:例如,在建筑过程中更改支撑桥梁的塔架数量不切实际。
增量开发意味着永远不会完成软件设计。设计在系统的整个生命周期中不断发生:开发人员应始终在思考设计问题。增量开发还意味着不断的重新设计。系统或组件的初始设计几乎从来都不是最好的。随着经验累积,不可避免地会产生更好的做事方式。作为软件开发人员,您应该始终在寻找机会来改进正在开发的系统的设计,并且应该计划将部分时间花费在设计改进上。
如果软件开发人员应始终考虑设计问题,而降低复杂性是软件设计中最重要的要素,则软件开发人员应始终考虑复杂性。这本书是关于如何使用复杂性来指导软件设计的整个生命周期。
这本书有两个总体目标。首先是描述软件复杂性的性质:“复杂性”是什么意思,为什么重要,以及当程序具有不必要的复杂性时如何识别?本书的第二个也是更具挑战性的目标是介绍可在软件开发过程中使用的技术,以最大程度地减少复杂性。不幸的是,没有简单的方法可以保证出色的软件设计。取而代之的是,我将提出一些与哲学紧密相关的高级概念,例如“类应该很深”或“定义不存在的错误”。这些概念可能不会立即确定最佳设计,但您可以使用它们来比较设计备选方案并指导您探索设计空间。
1.1 如何使用这本书
这里描述的许多设计原则有些抽象,因此如果不看实际的代码,可能很难理解它们。找到足够小的示例以包含在书中,但是又足够大以说明真实系统的问题是一个挑战(如果遇到好的示例,请发给我)。因此,这本书可能不足以让您学习如何应用这些原理。
使用本书的最佳方法是与代码审查结合使用。阅读其他人的代码时,请考虑它是否符合此处讨论的概念,以及它与代码的复杂性之间的关系。在别人的代码中比在您的代码中更容易看到设计问题。您可以使用此处描述的红色标记来发现问题并提出改进建议。查看代码还将使您接触到新的设计方法和编程技术。
改善设计技能的最好方法之一就是学会识别危险信号:信号表明一段代码可能比需要的复杂。在本书的过程中,我将指出一些危险信号,这些危险信号指示与每个主要设计问题有关的问题;最重要的内容总结在书的后面。然后,您可以在编码时使用它们:当看到红色标记时,停下来寻找可消除问题的替代设计。当您第一次尝试这种方法时,您可能必须尝试几种设计替代方案,然后才能找到消除危险信号的方案。不要轻易放弃:解决问题之前尝试的替代方法越多,您就会学到更多。随着时间的流逝,您会发现代码中的危险信号越来越少,并且您的设计越来越清晰。
在应用本书中的思想时,务必要节制和谨慎。每条规则都有例外,每条原则都有其局限性。如果您将任何设计创意都发挥到极致,那么您可能会陷入困境。精美的设计反映了相互竞争的思想和方法之间的平衡。有几章的标题为“太过分”,它们描述了如何在做得过大的事情上识别自己。
本书中几乎所有示例都是使用 Java 或 C++ 编写的,并且大部分讨论都是针对以面向对象的语言设计类的。但是,这些想法也适用于其他领域。几乎所有与方法有关的思想也可以应用于没有面向对象功能的语言中的功能,例如 C。设计思想还适用于除类之外的模块,例如子系统或网络服务。
在这种背景下,让我们详细讨论导致复杂性的原因以及如何简化软件系统。
解决复杂性的方法 1.使代码更简单和更明显。 2.封装它,使用时不必了解细节。
第 2 章 复杂性的本质
这本书是关于如何设计软件系统以最小化其复杂性。第一步是了解敌人。究竟什么是“复杂性”?您如何判断系统是否过于复杂?是什么导致系统变得复杂?本章将在较高层次上解决这些问题。后续章节将向您展示如何从较低的层次上根据特定的结构特征来识别复杂性。
识别复杂性的能力是至关重要的设计技能。它使您可以先找出问题,然后再付出大量努力,并可以在其他选择中做出正确的选择。判断一个设计是否简单比创建一个简单的设计要容易得多,但是一旦您认识到一个系统过于复杂,就可以使用该功能指导您的设计哲学走向简单。如果设计看起来很复杂,请尝试其他方法,看看是否更简单。随着时间的流逝,您会注意到某些技术往往会导致设计更简单,而其他技术则与复杂性相关。这将使您更快地制作更简单的设计。
本章还列出了一些基本假设,这些基本假设为本书的其余部分奠定了基础。后面的章节将采用本章的内容,并用其论证各种改进和结论。
2.1 复杂性的定义
出于本书的目的,我以实用的方式定义“复杂性”。复杂性与软件系统的结构有关,这使它很难理解和修改系统(复杂性是指那些让系统难以理解或修改的与系统相关的任何事物)。复杂性可以采取多种形式。例如,可能很难理解一段代码是如何工作的。可能需要花费很多精力才能实现较小的改进,或者可能不清楚必须修改系统的哪些部分才能进行改进;如果不引入其他错误,可能很难修复(也可以是不引入额外问题的情况下,很难修复一个bug)。如果一个软件系统难以理解和修改,那就很复杂。如果很容易理解和修改,那就很简单。
您还可以考虑成本和收益方面的复杂性(你还可以根据成本和收益来评估复杂性)。在复杂的系统中,要实施甚至很小的改进都需要大量的工作。在一个简单的系统中,可以用更少的精力实现更大的改进。
复杂性是开发人员在尝试实现特定目标时在特定时间点所经历的。它不一定与系统的整体大小或功能有关。人们通常使用“复杂”一词来描述具有复杂功能的大型系统,但是如果这样的系统易于使用,那么就本书而言,它并不复杂。当然,实际上几乎所有大型复杂的软件系统都很难使用,因此它们也符合我对复杂性的定义,但这不一定是事实。小型而不复杂的系统也可能非常复杂。
复杂性取决于最常见的活动。如果系统中有一些非常复杂的部分,但是几乎不需要触摸这些部分,那么它们对系统的整体复杂性不会有太大影响。为了用粗略的数学方法来表征:
系统的总体复杂度()由每个部分的复杂度()乘以开发人员在该部分上花费的时间()加权。在一个永远不会被看到的地方隔离复杂性几乎和完全消除复杂性一样好。
读者比作家更容易理解复杂性。如果您编写了一段代码,对您来说似乎很简单,但是其他人则认为它很复杂,那么它就是复杂的。当您遇到这种情况时,有必要对其他开发人员进行调查,以找出为什么代码对他们而言似乎很复杂;从您的观点与观点之间的脱节中可能可以学习一些有趣的课程。作为开发人员,您的工作不仅是创建可以轻松使用的代码,而且还要创建其他人也可以轻松使用的代码。
2.2 复杂性的症状
复杂性通过以下三种段落中描述的三种一般方式体现出来。这些表现形式中的每一个都使执行开发任务变得更加困难。
变更放大:复杂性的第一个征兆是,看似简单的变更需要在许多不同地方进行代码修改。例如,考虑一个包含几个页面的网站,每个页面显示带有背景色的横幅。在许多早期的网站中,颜色是在每个页面上明确指定的,如图 2.1(a)所示。为了更改此类网站的背景,开发人员可能必须手动修改每个现有页面;对于拥有数千个页面的大型网站而言,这几乎是不可能的。幸运的是,现代网站使用的方法类似于图 2.1(b),其中横幅颜色一次在中心位置指定,并且所有各个页面均引用该共享值。使用这种方法,可以通过一次修改来更改整个网站的标题颜色。
认知负荷:复杂性的第二个症状是认知负荷,这是指开发人员需要多少知识才能完成一项任务。较高的认知负担意味着开发人员必须花更多的时间来学习所需的信息,并且由于错过了重要的东西而导致错误的风险也更大。例如,假设 C 中的一个函数分配了内存,返回了指向该内存的指针,并假定调用者将释放该内存。这增加了使用该功能的开发人员的认知负担。如果开发人员无法释放内存,则会发生内存泄漏。如果可以对系统进行重组,以使调用者不必担心释放内存(分配内存的同一模块也负责释放内存),它将减少认知负担。(认知负荷出现在很多方面,例如很多方法的API,全局变量,不一致和模块间依赖)
系统设计人员有时会假设可以通过代码行来衡量复杂性。他们认为,如果一个实现比另一个实现短,那么它必须更简单;如果只需要几行代码就可以进行更改,那么更改必须很容易。但是,这种观点忽略了与认知负荷相关的成本。我已经看到了仅允许使用几行代码编写应用程序的框架,但是要弄清楚这些行是什么极其困难。有时,需要更多代码行的方法实际上更简单,因为它减少了认知负担。
(a) 直接硬编码 (b) 变量抽象 (c) 增加配置维度
Web pages ┌────────────┐ ┌────────────┐ ┌────────────────┐
│ │ bg = "red" │ │bg=bannerBg │ │bg=bannerBg │
│ ├────────────┤ ├────────────┤ │emph="darkred" │
│ │ bg = "red" │ │bg=bannerBg │ ├────────────────┤
│ ├────────────┤ ├────────────┤ │bg=bannerBg │
├───────────────►│ bg = "red" │ vs │bg=bannerBg │ vs ├────────────────┤
│ ├────────────┤ ├────────────┤ │bg=bannerBg │
│ │ ... │ │ ... │ ├────────────────┤
│ ├────────────┤ ├────────────┤ │bg=bannerBg │
│ │ bg = "red" │ │bg=bannerBg │ │emph="darkred" │
│ └────────────┘ └─────┬──────┘ └────────┬───────┘
│ │ │
│ │ │
│ ┌────▼─────┐ │
│ │bannerBg │◄─────────────────────┤
│ └────┬─────┘ │
│ │ │
│ ▼ │
│ ┌─────────┐ ┌─────────┐ │
└──────────────────────────────────────────►│ "red" │ │darkred │◄────────┘
└─────────┘ └─────────┘图 2.1:网站中的每个页面都显示一个彩色横幅。在(a)中,横幅的背景色在每页中都明确指定。在(b)中,共享变量保留背景色,并且每个页面都引用该变量。在(c)中,某些页面会显示其他用于强调的颜色,即横幅背景颜色的暗色;如果背景颜色改变,则强调颜色也必须改变。
未知的未知: 复杂性的第三个症状是,必须修改哪些代码才能完成任务,或者开发人员必须获得哪些信息才能成功地执行任务,这些都是不明显的。图 2.1(c)说明了这个问题。网站使用一个中心变量来确定横幅的背景颜色,所以它看起来很容易改变。但是,一些 Web 页面使用较暗的背景色来强调,并且在各个页面中明确指定了较暗的颜色。如果背景颜色改变,那么强调的颜色必须改变以匹配。不幸的是,开发人员不太可能意识到这一点,所以他们可能会更改中央 bannerBg 变量而不更新强调颜色。即使开发人员意识到这个问题,也不清楚哪些页面使用了强调色,因此开发人员可能必须搜索 Web 站点中的每个页面。
在复杂性的三种表现形式中,未知的未知是最糟糕的。一个未知的未知意味着你需要知道一些事情,但是你没有办法找到它是什么,甚至是否有一个问题。你不会发现它,直到错误出现后,你做了一个改变。更改放大是令人恼火的,但是只要清楚哪些代码需要修改,一旦更改完成,系统就会工作。同样,高的认知负荷会增加改变的成本,但如果明确要阅读哪些信息,改变仍然可能是正确的。对于未知的未知,不清楚该做什么,或者提出的解决方案是否有效。唯一确定的方法是读取系统中的每一行代码,这对于任何大小的系统都是不可能的。甚至这可能还不够,因为更改可能依赖于一个从未记录的细微设计决策。
良好设计的最重要目标之一就是使系统显而易见。这与高认知负荷和未知未知数相反。在一个显而易见的系统中,开发人员可以快速了解现有代码的工作方式以及进行更改所需的内容。一个显而易见的系统是,开发人员可以在不费力地思考的情况下快速猜测要做什么,同时又可以确信该猜测是正确的。第 18 章讨论使代码更明显的技术。
2.3 复杂性的原因
既然您已经了解了复杂性的高级症状以及为什么复杂性会使软件开发变得困难,那么下一步就是了解导致复杂性的原因,以便我们设计系统来避免这些问题。复杂性是由两件事引起的:依赖性和模糊性。本节从高层次讨论这些因素。随后的章节将讨论它们与低级设计决策之间的关系。
就本书而言,当无法孤立地理解和修改给定的一段代码时,便存在依赖关系。该代码以某种方式与其他代码相关,如果更改了给定代码,则必须考虑和/或修改其他代码。在图 2.1(a)的网站示例中,背景色在所有页面之间创建了依赖关系。所有页面都必须具有相同的背景,因此,如果更改一页的背景,则必须更改所有背景。依赖关系的另一个示例发生在网络协议中。通常,协议的发送方和接收方有单独的代码,但是它们必须分别符合协议。更改发送方的代码几乎总是需要在接收方进行相应的更改,反之亦然。
依赖关系是软件的基本组成部分,不能完全消除。实际上,我们在软件设计过程中有意引入了依赖性。每次编写新类时,都会围绕该类的 API 创建依赖关系。但是,软件设计的目标之一是减少依赖关系的数量,并使依赖关系保持尽可能简单和明显。
考虑网站示例。在每个页面分别指定背景的旧网站中,所有网页都是相互依赖的。新的网站通过在中心位置指定背景色并提供一个 API,供各个页面在呈现它们时检索该颜色,从而解决了该问题。新的网站消除了页面之间的依赖关系,但是它围绕 API 创建了一个新的依赖关系以检索背景色。幸运的是,新的依赖性更加明显:很明显,每个单独的网页都取决于 bannerBg 颜色,并且开发人员可以通过搜索其名称轻松找到使用该变量的所有位置。此外,编译器还有助于管理 API 依赖性:如果共享变量的名称发生变化,任何仍使用旧名称的代码都将发生编译错误。新的网站用一种更简单,更明显的方式代替了一种不明显且难以管理的依赖性。
复杂性的第二个原因是晦涩。当重要的信息不明显时,就会发生模糊。一个简单的例子是一个变量名,它是如此的通用,以至于它没有携带太多有用的信息(例如,时间)。或者,一个变量的文档可能没有指定它的单位,所以找到它的惟一方法是扫描代码,查找使用该变量的位置。晦涩常常与依赖项相关联,在这种情况下,依赖项的存在并不明显。例如,如果向系统添加了一个新的错误状态,可能需要向一个包含每个状态的字符串消息的表添加一个条目,但是对于查看状态声明的程序员来说,消息表的存在可能并不明显。不一致性也是造成不透明性的一个主要原因:如果同一个变量名用于两个不同的目的,那么开发人员就无法清楚地知道某个特定变量的目的是什么。
在许多情况下,由于文档不足而导致模糊不清。第 13 章讨论了这个主题。但是,模糊性也是设计问题。如果系统设计简洁明了,则所需的文档将更少。对大量文档的需求通常是一个警告,即设计不正确。减少模糊性的最佳方法是简化系统设计。
依赖性和模糊性共同构成了第 2.2 节中描述的三种复杂性表现。依赖性导致变化放大和高认知负荷。晦涩会产生未知的未知数,还会增加认知负担。如果我们找到最小化依赖关系和模糊性的设计技术,那么我们就可以降低软件的复杂性。
2.4 复杂度是递增的
复杂性不是由单个灾难性错误引起的;它堆积成许多小块。单个依赖项或模糊性本身不太可能显着影响软件系统的可维护性。之所以会出现复杂性,是因为随着时间的流逝,成千上万的小依赖性和模糊性逐渐形成。最终,这些小问题太多了,以至于对系统的每次可能更改都会受到其中几个问题的影响。
复杂性的增量性质使其难以控制。可以很容易地说服自己,当前更改所带来的一点点复杂性没什么大不了的。但是,如果每个开发人员对每种更改都采用这种方法,那么复杂性就会迅速累积。一旦积累了复杂性,就很难消除它,因为修复单个依赖项或模糊性本身不会产生很大的变化。为了减缓复杂性的增长,您必须采用第 3 章中讨论的“零容忍”理念。
2.5 结论
复杂性来自于依赖性和模糊性的积累。随着复杂性的增加,它会导致变化放大,高认知负荷和未知的未知数。结果,需要更多的代码修改才能实现每个新功能。此外,开发人员花费更多时间获取足够的信息以安全地进行更改,在最坏的情况下,他们甚至找不到所需的所有信息。最重要的是,复杂性使得修改现有代码库变得困难且冒险。
第 3 章 工作代码是不够的
好的软件设计中最重要的元素之一是您在执行编程任务时所采用的思维方式。许多组织都鼓励采取战术思维方式,着眼于使功能尽快运行。但是,如果您想要一个好的设计,则必须采取更具战略性的方法,在此上花费时间来制作干净的设计并解决问题。本章讨论了从长远来看,为什么战略方法可以产生更好的设计,而实际上却比战术方法便宜。
3.1 战术编程
大多数程序员以我称为战术编程的心态来进行软件开发(针对大多数的开发人员的编码时的思维方式,作者称之为战术式编码)。在战术方法中,您的主要重点是使某些功能正常工作,例如新功能或错误修复。乍一看,这似乎是完全合理的:还有什么比编写有效的代码更重要的呢?但是,战术编程几乎不可能产生出良好的系统设计。
战术编程的问题是它是短视的。如果您是战术编程人员,那么您将尝试尽快完成任务。也许您有一个艰难的期限。因此,为未来做计划不是优先事项。您不会花费太多时间来寻找最佳设计。您只想尽快使某件事起作用。您告诉自己,可以增加一些复杂性或引入一两个小错误,如果这样可以使当前任务更快地完成,则可以。(多数人还会自我安慰,如果可以让功能尽快上线的话,提高一些复杂度或者引入一两个小问题不是什么大不了的事情)
这就是系统变得复杂的方式。如上一章所述,复杂度是递增的。不是使系统复杂的特定事物,而是数十或数百个小事物的积累(复杂性的提升,不是由一个特定的事物引起的,而是由数十或成百的小事物积累导致的)。如果您进行战术编程(如果编码时总是使用战术式思维方式),则每个编程任务都会带来一些此类复杂性。为了快速完成当前任务,他们每个人似乎都是一个合理的折衷方案。但是,复杂性迅速累积,尤其是如果每个人都在战术上进行编程的时候。
不久之后,某些复杂性将开始引起问题,并且您将开始希望您没有采用这些早期的捷径。但是,您会告诉自己,使下一个功能正常工作比返回并重构现有代码更为重要。从长远来看,重构可能会有所帮助,但是肯定会减慢当前的任务。因此,您需要快速修补程序来解决遇到的任何问题。这只会增加复杂性,然后需要更多补丁。很快代码变得一团糟,但是到现在为止,情况已经很糟糕了,清理它需要花费数月的时间。您的日程安排无法容忍这种延迟,解决一个或两个问题似乎并没有太大的区别,因此您只是在战术上保持编程。
如果您从事大型软件项目的时间很长,我怀疑您在工作中已经看到了战术编程,并且遇到了导致的问题。一旦您沿着战术路线走,就很难改变。
几乎每个软件开发组织都有至少一个将战术编程发挥到极致的开发人员:战术龙卷风。战术龙卷风是一位多产的程序员,他抽出代码的速度比其他人快得多,但完全以战术方式工作。实施快速功能时,没有人能比战术龙卷风更快地完成任务。在某些组织中,管理层将战术龙卷风视为英雄。但是,战术龙卷风留下了毁灭的痕迹。他们很少被将来必须使用其代码的工程师视为英雄。通常,其他工程师必须清理战术龙卷风留下的混乱局面,这使得那些工程师(他们是真正的英雄)的进步似乎比战术龙卷风慢。
3.2 战略规划
成为一名优秀的软件设计师的第一步是要意识到 能跑起来的的代码是不够的。引入不必要的复杂性以更快地完成当前任务是不可接受的。最重要的是系统的长期结构。任何系统中的大多数代码都是通过扩展现有代码库编写的,因此,作为开发人员,最重要的工作就是促进这些将来的扩展。因此,尽管您的代码当然必须工作,但您不应将“工作代码”视为主要目标。您的主要目标必须是制作出出色的设计,并且这种设计也会起作用。这是 战略计划。
战略性编程需要一种投资心态。您必须花费时间来改进系统的设计,而不是采取最快的方式来完成当前的项目。这些投资会在短期内让您放慢脚步,但从长远来看会加快您的速度,如图 3.1 所示。
一些投资将是积极的。例如,值得花一些时间为每个新类找到一个简单的设计。而不是实施想到的第一个想法,请尝试几种替代设计并选择最简洁的设计。试想一下将来可能需要更改系统的几种方式,并确保设计容易。编写好的文档是主动投资的另一个例子。
其他投资将是被动的。无论您预先投入多少,设计决策中都不可避免地会出现错误。随着时间的流逝,这些错误将变得显而易见。发现设计问题时,不要只是忽略它或对其进行修补。花一些额外的时间来修复它。如果您进行战略性编程,则将不断对系统设计进行小幅改进。这与战术编程相反,在战术编程中,您不断增加一些复杂性,这些复杂性将来会引起问题。
3.3 投资多少?
那么,正确的投资额是多少?大量的前期投资(例如尝试设计整个系统)将不会有效。这是瀑布方法,我们知道它不起作用。随着您对系统的了解,理想的设计趋于零碎出现。因此,最好的方法是连续进行大量小额投资 。我建议您将总开发时间的 10%到 20%用于投资。该金额足够小,不会对您的日程安排产生重大影响,但又足够大,可以随着时间的推移产生重大收益。因此,您的初始项目将比纯战术方法花费 10-20%的时间。额外的时间将带来更好的软件设计,并且您将在几个月内开始体验到这些好处。不久之后,您的开发速度将比战术编程快至少 10–20%。在这一点上,您的投资将免费:您过去投资的收益将节省足够的时间来支付未来投资的费用。您将迅速收回初始投资的成本。图 3.1 说明了这种现象。
图 3.1:一开始,战术性的编程方法将比战略性方法更快地取得进展。但是,在战术方法下,复杂性积累得更快,从而降低了生产率。随着时间的流逝,战略方针会带来更大的进步。注意:此图仅用于定性说明;我不知道对曲线精确形状的任何经验测量。
相反,如果您进行战术编程,则可以将第一个项目完成的速度提高 10%到 20%,但是随着时间的推移,复杂性的累积会降低开发速度。不久之后,您的编程速度至少会降低 10–20%。您将很快退回在开始时节省的所有时间,并且在系统的整个生命周期中,与采用策略性方法相比,您的开发速度将更加缓慢。如果您从未使用过严重降级的代码库,请与有经验的人联系。他们会告诉您不良的代码质量会使开发速度至少降低 20%。
3.4 创业与投资
在某些环境中,强大的力量与战略方法背道而驰。例如,早期的初创公司感到巨大的压力,需要尽快发布其早期版本。在这些公司中,甚至 10%至 20%的投资似乎也负担不起。结果,许多初创公司采取了战术性的方法,在设计上花费了很少的精力,而在问题出现时则花费了更少的精力进行清理。他们认为,如果成功,他们将有足够的钱聘请额外的工程师来清理问题,从而使其合理化。
如果您是一家朝着这个方向发展的公司,则应该意识到,一旦代码库变成了意大利面条,几乎是不可能修复的。您可能会为产品的使用寿命付出高昂的开发成本。此外,好的(或坏的)设计的回报很快就会到来,因此战术方法很有可能甚至不会加快您的首个产品发布的速度。
要考虑的另一件事是,公司成功的最重要因素之一就是工程师的素质。降低开发成本的最佳方法是聘请优秀的工程师:他们的成本不会比普通工程师高很多,但生产率却高得多。但是,最好的工程师对良好的设计深感兴趣。如果你的代码库很糟糕,消息传出去,你将更更难招募到好的工程师。最终可能还是只能使用普通的工程师。这将增加您的未来成本,并可能导致系统结构进一步退化。
Facebook 是一个鼓励战术编程的创业公司的例子。多年来,公司的座右铭是“快速行动并打破困境”。鼓励刚大学毕业的新工程师立即深入公司的代码库;工程师在工作的第一周将承诺投入生产是很正常的。从积极的一面来看,Facebook 作为一家赋予员工权力的公司而享有声誉。工程师拥有极大的自由度,并且几乎没有任何规则和限制。
Facebook 作为一家公司已经取得了令人瞩目的成功,但是由于该公司的战术方法,其代码库受到了影响(同样由于公司的战术编程推广,Facebook的代码库深受其害)。许多代码不稳定且难以理解,几乎没有注释或测试,并且使用起来很痛苦。随着时间的流逝,该公司意识到其文化是不可持续的。最终,Facebook 改变了座右铭,即“以坚实的基础架构快速移动”,以鼓励其工程师在良好的设计上进行更多的投资。Facebook 是否能够成功清除多年来战术编程中积累的问题还有待观察。
为了公平起见,我应该指出,Facebook 的代码可能并不比初创公司的平均水平差很多。战术编程在初创企业中司空见惯。Facebook 恰好是一个特别明显的例子。
幸运的是,通过战略方法也有可能在硅谷取得成功。Google 和 VMware 与 Facebook 差不多同时成长,但是这两家公司都采用了更具战略意义的方法。两家公司都非常重视高质量的代码和良好的设计,并且两家公司都开发了复杂的产品,这些产品通过可靠的软件系统解决了复杂的问题。公司的强大技术文化在硅谷广为人知。很少有其他公司可以与他们竞争聘请顶级技术人才。
这些例子表明,一家公司可以成功使用任何一种方法。但是,在一家关心软件设计并拥有清晰代码基础的公司中工作会有趣得多。
3.5 结论
好的设计不是免费的。它必须是您不断投资的东西,这样小问题才不会累积成大问题。幸运的是,好的设计最终会收回成本,而且比您想象的要早。
始终如一地运用战略方法并将投资视为当下而不是未来要做的事情至关重要。当您陷入危机时,很容易推迟清理,直到危机结束之后。但是,这是滑坡效应。在当延迟之后,几乎肯定会再出现一次。一旦开始延迟设计改进,就很容易使延迟永久化,并使您的文化陷入战术方法中。您等待解决设计问题的时间越长,问题就会变得越大;解决方案变得更加令人生畏,这使得轻松推迟解决方案变得更加容易。最有效的方法是,每位工程师都对良好的设计进行连续的少量投资。
第 4 章 模块应该是深的
管理软件复杂性最重要的技术之一就是设计系统,以便开发人员在任何给定时间 只需要面对整体复杂性的一小部分。这种方法称为模块化设计,本章介绍其基本原理。
4.1 模块化设计
在模块化设计中,软件系统被分解为相对独立的模块集合。模块可以采用多种形式,例如类,子系统或服务。在理想的世界中,每个模块都将完全独立于其他模块:开发人员可以在任何模块中工作,而无需了解任何其他模块。在这种情况下,系统的复杂性就是其最糟糕的模块的复杂性。
不幸的是,这种理想是无法实现的。模块必须通过调用彼此的函数或方法来协同工作。结果,模块必须相互了解。模块之间将存在依赖关系:如果一个模块发生更改,则可能需要更改其他模块以进行匹配。例如,方法的参数在方法与调用该方法的任何代码之间创建依赖关系。如果必需的参数更改,则必须修改该方法的所有调用以符合新的签名。依赖关系可以采用许多其他形式,并且它们可能非常微妙。模块化设计的目标是最大程度地 减少模块之间的依赖性。
为了管理依赖关系,我们将每个模块分为两个部分:接口和实现。接口包括了在不同模块工作的开发者为了使用给定模块必须知道的所有内容。通常,接口描述模块做什么,而不描述模块如何做。该实现由执行接口所承诺的代码组成。在特定模块中工作的开发人员必须了解该模块的接口和实现,以及由给定模块调用的任何其他模块的接口。除了正在使用的模块以外,开发人员无需了解其他模块的实现。
考虑一个实现平衡树的模块。该模块可能包含复杂的代码,以确保树保持平衡。但是,此复杂性对于模块使用者而言是不可见的。用户可以看到一个相对简单的接口,用于调用在树中插入,删除和获取节点的操作。要调用插入操作,调用者只需提供新节点的键和值即可。遍历树和拆分节点的机制在接口中不可见。
就本书而言,模块是具有接口和实现的任何代码单元。面向对象编程语言中的每个类都是一个模块。类中的方法或非面向对象语言中的函数也可以视为模块:每个模块都有一个接口和一个实现,并且可以将模块化设计技术应用于它们。更高级别的子系统和服务也是模块。它们的接口可能采用不同的形式,例如内核调用或 HTTP 请求。本书中有关模块化设计的许多讨论都集中在设计类上,但是技术和概念也适用于其他种类的模块。
最好的模块是那些其接口比其实现简单得多的模块。这样的模块具有两个优点。首先,一个简单的接口可以将模块强加于系统其余部分的复杂性降至最低。其次,如果以不更改其接口的方式修改了一个模块,则该修改不会影响其他模块。如果模块的接口比其实现简单得多,则可以在不影响其他模块的情况下更改模块的许多方面。
4.1 接口中有什么?
模块的接口包含两种信息:正式信息和非正式信息。接口的形式部分在代码中明确指定,并且其中一些可以通过编程语言检查其正确性。例如,方法的形式接口是其签名,其中包括其参数的名称和类型,其返回值的类型以及有关该方法引发的异常的信息。大多数编程语言都确保对方法的每次调用都提供正确数量和类型的参数以匹配其签名。类的形式接口包括其所有公共方法的签名以及任何公共变量的名称和类型。
每个接口还包括非正式元素。这些没有以编程语言可以理解或执行的方式指定。接口的非正式部分包括其高级行为,例如,函数删除由其参数之一命名的文件的事实。如果对类的使用存在限制(也许必须先调用一种方法),则这些约束也是类接口的一部分。通常,如果开发人员需要了解特定信息才能使用模块,则该信息是模块接口的一部分。接口的非正式方面只能使用注释来描述,而编程语言不能确保描述是完整或准确的 1。对于大多数接口,非正式方面比正式方面更大,更复杂。
明确指定接口的好处之一是,它可以准确指示开发人员使用关联模块所需要知道的内容。这有助于消除第 2.2 节中描述的“未知的未知”问题。
4.3 抽象
术语抽象与模块化设计的思想紧密相关。抽象是实体的简化视图,其中省略了不重要的细节。抽象是有用的,因为它们使我们更容易思考和操纵复杂的事物。
在模块化编程中,每个模块以其接口的形式提供抽象。该接口提供了模块功能的简化视图;从模块抽象的角度来看,实现的细节并不重要,因此在接口中将其省略。
在抽象的定义中,“无关紧要”一词至关重要。从抽象中忽略的不重要的细节越多越好。但是,一个细节只有在不重要的情况下才能从抽象中省略。有两种错误的抽象方式。首先,它包含并非真正重要的细节。当这种情况发生时,它会使抽象变得不必要的复杂,从而增加了使用抽象的开发人员的认知负担。第二个错误是抽象忽略了真正重要的细节。这导致模糊不清:仅查看抽象的开发人员将不会获得正确使用抽象所需的全部信息。忽略重要细节的抽象是错误的抽象:它可能看起来很简单,但实际上并非如此。(设计抽象的重要一点就是识别重要性,并在设计过程中,将重要信息的数量尽量减到最少)
例如,考虑一个文件系统。文件系统提供的抽象省略了许多细节,例如用于选择存储设备上的哪些块用于给定文件中的数据的机制。这些详细信息对于文件系统的用户而言并不重要(只要系统提供足够的性能即可)。但是,文件系统实现的一些细节对用户很重要。大多数文件系统将数据缓存在主内存中,并且它们可能会延迟将新数据写入存储设备以提高性能。一些应用程序(例如数据库)需要确切地知道何时将数据写入存储设备,因此它们可以确保在系统崩溃后将保留数据。因此,将数据刷新到辅助存储的规则必须在文件系统的接口中可见。
我们依赖抽象来管理复杂性,这不仅仅体现在编程中,而且在我们日常生活的方方面面普遍存在。微波炉包含复杂的电子设备,可将交流电转换为微波辐射并将该辐射分布到整个烹饪腔中。幸运的是,用户看到了一个简单得多的抽象,它由几个按钮控制微波的定时和强度。汽车提供了一种简单的抽象概念,使我们可以在不了解电动机,电池电源管理,防抱死制动,巡航控制等机制的情况下驾驶它们。
4.4 深度模块
最好的模块是那些提供强大功能但具有简单接口的模块。我用“深入”一词来描述这样的模块。为了形象化深度的概念,假设每个模块都由一个矩形表示,如图 4.1 所示。每个矩形的面积与模块实现的功能成比例。矩形的顶部边缘代表模块的接口;边缘的长度表示接口的复杂性。最好的模块很深:它们在简单的接口后隐藏了许多功能。深度模块是一个很好的抽象,因为其内部复杂性的很小一部分对其用户可见。
图 4.1:深浅模块。最好的模块很深:它们允许通过简单的接口访问许多功能。浅层模块是具有相对复杂的接口的模块,但功能不多:它不会掩盖太多的复杂性。
模块深度是考虑成本与收益的一种方式。模块提供的好处是其功能。模块的成本(就系统复杂性而言)是其接口。模块的接口代表了模块强加给系统其余部分的复杂性:接口越小越简单,引入的复杂性就越小。最好的模块是那些收益最大,成本最低的模块。接口是好的,但更多或更大的接口不一定更好!
Unix 操作系统及其后代(例如 Linux)提供的文件 I/O 机制是深层接口的一个很好的例子。I/O 只有五个基本系统调用,带有简单签名:
int open(const char* path, int flags, mode_t permissions);
ssize_t read(int fd, void* buffer, size_t count);
ssize_t write(int fd, const void* buffer, size_t count);
off_t lseek(int fd, off_t offset, int referencePosition);
int close(int fd);开放系统调用采用分层文件名,例如 /a/b/c,并返回一个整数 文件描述符,该描述符用于引用打开文件。open 的其他自变量提供可选信息,例如是否正在打开文件以进行读取或写入,如果不存在现有文件则是否应创建新文件,以及如果创建新文件则具有文件的访问权限。读写系统调用在应用程序内存和文件的缓冲区之间传输信息。close 结束对文件的访问。大多数文件是按顺序访问的,因此这是默认设置。但是,可以通过调用 lseek 系统调用来更改当前访问位置来实现随机访问。
Unix I/O 接口的现代实现需要成千上万行代码,这些代码可以解决诸如以下的复杂问题:
- 如何在磁盘上表示文件以便有效访问?
- 如何存储目录,以及如何处理分层路径名以查找它们所引用的文件?
- 如何强制执行权限,以使一个用户无法修改或删除另一用户的文件?
- 如何实现文件访问?例如,如何在中断处理程序和后台代码之间划分功能,以及这两个元素如何安全通信?
- 在同时访问多个文件时使用什么调度策略?
- 如何将最近访问的文件数据缓存在内存中以减少磁盘访问次数?
- 如何将各种不同的辅助存储设备(例如磁盘和闪存驱动器)合并到单个文件系统中?
所有这些问题,以及更多的问题,都由 Unix 文件系统实现来解决。对于调用系统调用的程序员来说,它们是不可见的。多年来,Unix I/O 接口的实现已经发生了根本的发展,但是五个基本内核调用并没有改变。
深度模块的另一个示例是诸如 Go 或 Java 之类的语言中的垃圾收集器。这个模块根本没有接口。它在后台进行隐形操作以回收未使用的内存。由于将垃圾收集消除了用于释放对象的接口,因此向系统中添加垃圾回收实际上会缩小其总体接口。垃圾收集器的实现非常复杂,但是使用该语言的程序员无法发现这种复杂性。
诸如 Unix I/O 和垃圾收集器之类的深层模块提供了强大的抽象,因为它们易于使用,但隐藏了巨大的实现复杂性。
4.5 浅模块
另一方面,浅层模块是其接口与其提供的功能相比相对复杂的模块。例如,实现链表的类很浅。操作链表不需要太多代码(插入或删除元素仅需几行),因此链表抽象不会隐藏很多细节。链表接口的复杂度几乎与其实现的复杂度一样高。浅类有时是不可避免的,但是它们在管理复杂性方面没有提供太多帮助。
这是一个浅层方法的极端示例,该浅层方法来自软件设计类的项目:
private void addNullValueForAttribute(String attribute) {
data.put(attribute, null);
}从管理复杂性的角度来看,此方法会使情况变得更糟,而不是更好。该方法不提供任何抽象,因为其所有功能都可以通过其接口看到。例如,调用者可能需要知道该属性将存储在 data 变量中。考虑接口并不比考虑完整实现简单。如果正确记录了该方法,则文档将比该方法的代码长。与调用方直接操作数据变量相比,调用该方法所花费的击键甚至更多。该方法增加了复杂性(以供开发人员学习的新接口的形式),但没有提供任何补偿。
浅层模块是指其接口相对于它提供的功能来说比较复杂的模块。浅层模块在对抗复杂性方面无济于事,因为它们提供的好处(不必了解它们在内部如何工作)被学习和使用其接口的成本所抵消。小模块往往很浅。
4.6 Classitis
不幸的是,深度类的价值在今天并未得到广泛认可。编程中的传统观点是,类应该小而不是深。经常告诉学生,类设计中最重要的事情是将较大的类分成较小的类。对于方法,通常会给出相同的建议:“任何长于 N 行的方法都应分为多种方法”(N 可以低至 10)。这种方法导致了大量的浅类和方法,这增加了整体系统的复杂性。
“类应该小”的极端做法是我称之为“类炎”的综合症,这是由于错误地认为“类是好的,所以类越多越好”。在遭受类炎的系统中,鼓励开发人员最小化每个新类的功能:如果您想要更多的功能,请引入更多的类。分类炎可能导致个别地简单的分类,但是却增加了整个系统的复杂性。小类不会贡献太多功能,因此必须有很多小类,每个小类都有自己的接口。这些接口的累积会在系统级别产生巨大的复杂性。小类也导致冗长的编程风格,这是由于每个类都需要样板。
4.7 示例:Java 和 Unix I/O
如今,最常见的分类病实例之一是 Java 类库。Java 语言不需要很多小类,但是分类文化似乎已在 Java 编程社区中扎根。例如,要打开文件以便从文件中读取序列化的对象,必须创建三个不同的对象:
FileInputStream fileStream = new FileInputStream(fileName);
BufferedInputStream bufferedStream = new BufferedInputStream(fileStream);
ObjectInputStream objectStream = new ObjectInputStream(bufferedStream);FileInputStream 对象仅提供基本的 I/O:它不能执行缓冲的 I/O,也不能读取或写入序列化的对象。BufferedInputStream 对象将缓冲添加到 FileInputStream,而 ObjectInputStream 添加了读取和写入序列化对象的功能。一旦文件被打开,上面代码中的前两个对象 fileStream 和 bufferedStream 将永远不会被使用。以后的所有操作都使用 objectStream。
特别令人烦恼(并且容易出错)的是,必须通过创建一个单独的 BufferedInputStream 对象来显式请求缓冲。如果开发人员忘记创建该对象,将没有缓冲,并且 I/O 将变慢。也许 Java 开发人员会争辩说,并不是每个人都希望对文件 I/O 使用缓冲,因此不应将其内置到基本机制中。他们可能会争辩说,最好分开保持缓冲,以便人们可以选择是否使用它。提供选择是好的,但是 应该设计接口以使常见情况尽可能简单 (请参阅第 6 页的公式)。几乎每个文件 I/O 用户都希望缓冲,因此默认情况下应提供缓冲。对于不需要缓冲的少数情况,该库可以提供一种禁用它的机制。
相反,Unix 系统调用的设计者使常见情况变得简单。例如,他们认识到顺序 I/O 是最常见的,因此他们将其作为默认行为。使用 lseek 系统调用,随机访问仍然相对容易实现,但是仅执行顺序访问的开发人员无需了解该机制。如果一个接口具有许多功能,但是大多数开发人员只需要了解其中的一些功能,那么该接口的有效复杂性就是常用功能的复杂性。
4.8 结论
通过将模块的接口与其实现分开,我们可以将实现的复杂性从系统的其余部分中隐藏出来。模块的用户只需要了解其接口提供的抽象。设计类和其他模块时,最重要的问题是使它们更深,以使它们具有适用于常见用例的简单接口,但仍提供重要的功能。这样做能最大限度地隐藏复杂性。
第 5 章 信息隐藏(和泄漏)
第四章认为模块应该很深。本章及随后的其他章节讨论了创建深层模块的技术。
5.1 信息隐藏
实现深层模块最重要的技术是信息隐藏。该技术最早由 David Parnas2 描述。基本思想是每个模块应封装一些知识,这些知识代表设计决策。该知识嵌入在模块的实现中,但不会出现在其接口中,因此其他模块不可见。
隐藏在模块中的信息通常包含有关如何实现某种机制的详细信息。以下是一些信息可能隐藏在模块中的示例:
- 如何在 B 树中存储信息,以及如何有效地访问它。
- 如何识别文件中每个逻辑块相对应的物理磁盘块。
- 如何实现 TCP 网络协议。
- 如何在多核处理器上调度线程。
- 如何解析 JSON 文档。
隐藏的信息包括与该机制有关的数据结构和算法。它还可以包含较低级别的详细信息(例如页面大小),还可以包含更抽象的较高级别的概念,例如大多数文件较小的假设。
信息隐藏在两个方面降低了复杂性。首先,它简化了模块的接口。接口用更简单、更抽象的方式反映了模块的功能,并隐藏了细节。这减少了使用该模块的开发人员的认知负担。例如,使用 B-tree 类的开发人员不需要考虑树中节点的理想扇出,也不需要考虑如何保持树的平衡。其次,信息隐藏使系统更容易演化。如果隐藏了一段信息,那么在包含该信息的模块之外就不存在对该信息的依赖,因此与该信息相关的设计更改将只影响一个模块。例如,如果 TCP 协议发生了变化(例如,为了引入一种新的拥塞控制机制),协议的实现就必须进行修改,但是在使用 TCP 发送和接收数据的高级代码中不需要进行任何修改。
设计新模块时,应仔细考虑可以在该模块中隐藏哪些信息。如果您可以隐藏更多信息,则还应该能够简化模块的接口,这会使模块更深。
注意:通过声明变量和方法为私有来隐藏类中的变量和方法与信息隐藏不是同一回事。私有元素可以帮助隐藏信息,因为它们使无法从类外部直接访问项目。但是,私有属性仍可以通过公共方法(如 getter 和 setter 方法)公开。发生这种情况时,私有属性的性质和用法就如同公共属性一样是公开的。
信息隐藏的最佳形式是将信息完全隐藏在模块中,从而使该信息对模块的用户无关且不可见。但是,部分信息隐藏也具有价值。例如,如果一个特定的特性或信息只被少数的类使用者所需要,并且它是通过不同的方法访问的,所以在最常见的用例中它是不可见的,那么这个信息大部分是隐藏的。与将信息暴露给所有类使用者相比, 这种方式会产生更少的依赖。
5.2 信息泄漏
信息隐藏的反面是信息泄漏。当一个设计决策反映在多个模块中时,就会发生信息泄漏。这在模块之间创建了依赖关系:对该设计决策的任何更改都将要求对所有涉及的模块进行更改。如果一条信息反映在模块的接口中,则根据定义,该信息已经泄漏;因此,更简单的接口往往与更好的信息隐藏相关。但是,即使信息未出现在模块的接口中,也可能会泄漏信息。假设两个类都具有特定文件格式的知识(也许一个类读取该格式的文件,而另一个类写入它们)。即使两个类都不在其接口中公开该信息,它们都依赖于文件格式:如果格式更改,则两个类都将需要修改。像这样的后门泄漏比通过接口泄漏更有害,因为它并不明显。
信息泄漏是软件设计中最重要的危险信号之一。作为一个软件设计师,你能学到的最好的技能之一就是对信息泄露的高度敏感性。如果您在类之间遇到信息泄漏,请自问“我如何才能重新组织这些类,使这些特定的知识只影响一个类?”如果受影响的类相对较小,并且与泄漏的信息紧密相关,那么将它们合并到一个类中是有意义的。另一种可能的方法是从所有受影响的类中提取信息,并创建一个只封装这些信息的新类。但是,这种方法只有在您能够找到一个从细节中抽象出来的简单接口时才有效;如果新类通过其接口公开了大部分知识,那么它就不会提供太多的价值(您只是用通过接口的泄漏替换了后门泄漏)。
当在多个地方使用相同的知识时,例如两个都理解特定类型文件格式的不同类,就会发生信息泄漏。
5.3 时间分解
信息泄漏的一个常见原因是我称为时间分解的设计风格。在时间分解中,系统的结构对应于操作将发生的时间顺序。考虑一个应用程序,该应用程序以特定格式读取文件,修改文件内容,然后再次将文件写出。通过时间分解,该应用程序可以分为三类:一类用于读取文件,另一类用于执行修改,第三类用于写出新版本。文件读取和文件写入步骤都具有有关文件格式的知识,这会导致信息泄漏。解决方案是将用于读写文件的核心机制结合到一个类中。该类将在应用程序的读取和写入阶段使用。因为在编写代码时通常会想到必须执行操作的顺序, 所以很容易陷入时间分解的陷阱。但是,大多数设计决策会在应用程序的整个生命周期中的多个不同时刻表现出来。结果,时间分解常常导致信息泄漏。
顺序通常很重要,因此它将反映在应用程序中的某个位置。但是,除非该结构与信息隐藏保持一致(也许不同阶段使用完全不同的信息),否则不应将其反映在模块结构中。在设计模块时,应专注于执行每个任务所需的知识,而不是任务发生的顺序。
在时间分解中,执行顺序反映在代码结构中:在不同时间发生的操作在不同的方法或类中。如果相同的知识在不同的执行点使用,它会在多个位置被编码,从而导致信息泄漏。
5.4 示例:HTTP 服务器
为了说明信息隐藏中的问题,让我们考虑由学生在软件设计课程中实现 HTTP 协议的设计决策。看到他们做得好的事情以及遇到问题的地方都是很有用的。
HTTP 是 Web 浏览器用来与 Web 服务器通信的机制。当用户单击 Web 浏览器中的链接或提交表单时,浏览器使用 HTTP 通过网络将请求发送到 Web 服务器。服务器处理完请求后,会将响应发送回浏览器。该响应通常包含要显示的新网页。HTTP 协议指定了请求和响应的格式,两者均以文本形式表示。图 5.1 显示了描述表单提交的 HTTP 请求示例。要求课程中的学生实现一个或多个类,以使 Web 服务器可以轻松地接收传入的 HTTP 请求并发送响应。
Method URL Parameter(s) Protocol Version
↓ ↓ ↓ ↓
POST /comments/create?photo_id=246 HTTP/1.1 ┐
Host: www.example.com │
User-Agent: Mozilla/5.0 │
Accept: text/html, */* ├ Headers
Accept-Language: en-us │
Accept-Charset: ISO-8859-1,utf-8 │
Content-Length: 40 ┘
comment=what+a+cute+baby%21&priority=low ← Body图 5.1:HTTP 协议中的 POST 请求包含通过 TCP 套接字发送的文本。每个请求都包含一个初始行,一个由空行终止的标头集合以及一个可选主体。初始行包含请求类型(POST 用于提交表单数据),指示操作(/comments/create)和可选参数(photo_id 的值为 246)的 URL,以及发送方使用的 HTTP 协议版本。每个标题行由一个名称(例如 Content-Length)及其后的值组成。对于此请求,正文包含其他参数(注释和优先级)。
5.5 示例:太多的类
学生最常犯的错误是将他们的代码分成大量的浅层类,这导致了类之间的信息泄漏。一个组使用两种不同的类来接收 HTTP 请求。第一类将来自网络连接的请求读取为字符串,第二类将字符串解析。这是时间分解的一个示例(“首先读取请求,然后解析它”)。发生信息泄漏是因为无法解析大量消息就无法读取 HTTP 请求。例如,Content-Length 标头指定了请求主体的长度,因此必须对标头进行解析才能计算总请求长度。结果,这两个类都需要了解 HTTP 请求的大多数结构,并且解析代码在两个类中都是重复的。这种方法也给调用方带来了额外的复杂性,他们必须以特定的顺序调用不同类中的两个方法来接收请求。
由于这些类共享大量信息,因此最好将它们合并为一个同时处理请求读取和解析的类。由于它将请求格式的所有知识隔离在一个类中,因此它提供了更好的信息隐藏,并且还为调用者提供了一个更简单的接口(只是一种调用方法)。
此示例说明了软件设计中的一般主题:通常可以通过使类稍大一些来改善信息隐藏。这样做的一个原因是将与特定功能相关的所有代码(例如,解析 HTTP 请求)组合在一起,以便生成的类包含与该功能相关的所有内容。增加类大小的第二个原因是提高接口的级别。例如,与其为计算的三个步骤中的每一个步骤使用单独的方法,不如使用一种方法来执行整个计算。这样可以简化接口。这两个优点都适用于上一段的示例:组合类将与解析 HTTP 请求相关的所有代码组合在一起,并且用一个替换了两个外部可见的方法。组合后的类比原有的类都更深。
当然,可以将较大的类的概念考虑得太远(例如整个应用程序的单个类)。第 9 章将讨论将代码分成多个较小的类的合理条件。
5.6 示例:HTTP 参数处理
服务器收到 HTTP 请求后,服务器需要访问该请求中的某些信息。图 5.1 中处理请求的代码可能需要知道 photo_id 参数的值。参数可以在请求的第一行中指定(图 5.1 中的 photo_id),有时也可以在正文中指定(图 5.1 中的注释和优先级)。每个参数都有一个名称和一个值。参数的值使用一种称为 URL 编码的特殊编码。例如,在图 5.1 中的注释值中,“ +”代表空格字符,“%21”代替“!”。为了处理请求,服务器将需要某些参数的值,并且希望它们采用未编码的形式。
关于参数处理,大多数学生项目都做出了两个不错的选择。首先,他们认识到服务器应用程序不在乎是否在标题行或请求的正文中指定了参数,因此他们对调用者隐藏了这种区别,并将两个位置的参数合并在一起。其次,他们隐藏了 URL 编码的知识:HTTP 解析器在将参数值返回到 Web 服务器之前先对其进行解码,以便图 5.1 中的 comment 参数的值将返回 “What a cute baby!”,而不是 “What+a+cute+baby%21”)。在这两种情况下,信息隐藏都使使用 HTTP 模块的代码的 API 更加简单。
但是,大多数学生使用的接口返回的参数太浅,这导致丢失信息隐藏的机会。大多数项目使用 HTTPRequest 类型的对象来保存已解析的 HTTP 请求,并且 HTTPRequest 类具有一种类似于以下方法的单个方法来返回参数:
该方法不是返回单个参数,而是返回内部用于存储所有参数的映射的引用。这个方法是浅层的,它公开了 HTTPRequest 类用来存储参数的内部表示。对该表示的任何更改都将导致接口的更改,这将需要对所有调用者进行修改。在修改实现时,更改通常涉及关键数据结构表示的更改(例如,为了提高性能)。因此,尽量避免暴露内部数据结构是很重要的。这种方法还为调用者提供了更多的工作:调用者必须首先调用 getParams,然后必须调用另一个方法来从映射中检索特定的参数。最后,调用者必须意识到他们不应该修改 getParams 返回的映射,因为这会影响 HTTPRequest 的内部状态。
这是一个用于检索参数值的更好的接口:
public String getParameter(String name) { ... }
public int getIntParameter(String name) { ... }getParameter 以字符串形式返回参数值。它提供了一个比上面的 getParams 更深的接口;更重要的是,它隐藏了参数的内部表示。getIntParameter 将参数的值从 HTTP 请求中的字符串形式转换为整数(例如,图 5.1 中的 photo_id 参数)。这使调用者不必单独请求字符串到整数的转换,并且对调用者隐藏了该机制。如果需要,可以定义其他数据类型的其他方法,例如 getDoubleParameter。(如果所需的参数不存在,或者无法将其转换为所请求的类型,则所有这些方法都将引发异常;上面的代码中省略了异常声明)。
5.7 示例:HTTP 响应中的默认值
HTTP 项目还必须提供对生成 HTTP 响应的支持。学生在该领域中最常见的错误是默认值不足。每个 HTTP 响应必须指定一个 HTTP 协议版本。一个组要求呼叫者在创建响应对象时明确指定此版本。但是,响应版本必须与请求对象中的版本相对应,并且在发送响应时必须已将请求作为参数传递(它指示将响应发送到何处)。因此,HTTP 类自动提供响应版本更为有意义。调用者不太可能知道要指定哪个版本,并且如果调用者确实指定了一个值,则可能导致 HTTP 库和调用者之间的信息泄漏。HTTP 响应还包括一个 Date 标头,用于指定发送响应的时间;HTTP 库也应该为此提供一个合理的默认值。
默认值说明了应该设计接口以使常见情况尽可能简单的原则。它们还是隐藏部分信息的一个示例:在正常情况下,调用者无需知道默认项的存在。在极少数情况下,调用方需要覆盖默认值,它必须知道该值,并且可以调用特殊方法来对其进行修改。
只要有可能,类就应该“做正确的事”,而无需明确要求。默认值就是一个例子。第 26 页上的 Java I/O 示例以负面方式说明了这一点。普遍希望在文件 I/O 中缓冲,以至于没有人需要明确要求它,甚至不知道它的存在。I/O 类应该做正确的事情并自动提供它。最好的功能是您甚至不知道它们存在的功能。
如果一个常用特性的 API 迫使用户了解其他很少使用的特性,这将增加不需要这些很少使用的特性的用户的认知负荷。
5.8 信息隐藏在类中
本章中的示例着重于信息隐藏,因为它与类的外部可见 API 有关,但是信息隐藏也可以应用于系统中的其他级别,例如类内。尝试在一个类中设计私有方法,以便每个方法都封装一些信息或功能,并将其隐藏在类的其余部分中。此外,请尽量减少使用每个实例变量的位置数量。有些变量可能需要在整个类中广泛使用,但是其他变量可能只需要在少数地方使用;如果可以减少使用变量的位置的数量,则将消除类内的依赖关系并降低其复杂性。
5.9 走得太远
仅当在其模块外部不需要隐藏信息时,隐藏信息才有意义。如果模块外部需要该信息,则不得隐藏它。假设模块的性能受某些配置参数的影响,并且模块的不同用途将需要对参数进行不同的设置。在这种情况下,将参数暴露在模块的接口中很重要,以便可以对其进行适当的调整。作为软件设计师,您的目标应该是最大程度地减少模块外部所需的信息量。例如,如果模块可以自动调整其配置,那将比公开配置参数更好。但是,重要的是要识别模块外部需要哪些信息,并确保将其公开。
5.10 结论
信息隐藏和深层模块密切相关。如果模块隐藏了很多信息,则往往会增加模块提供的功能,同时还会减少其接口。这使模块更深。相反,如果一个模块没有隐藏太多信息,则它要么功能不多,要么接口复杂。无论哪种方式,模块都是浅的。
将系统分解为模块时,请尽量不要受运行时操作顺序的影响。这将使您沿着时间分解的路径前进,这将导致信息泄漏和模块浅。相反,请考虑执行应用程序任务所需的不同知识,并设计每个模块以封装这些知识中的一个或几个。这将产生一个干净简单的深模块设计。
第 6 章 通用模块更深入
设计新模块时,您将面临的最普遍的决定之一就是是以通用还是专用方式实现它。有人可能会争辩说,您应该采用通用方式,在这种方式中,您将实现一种可用于解决广泛问题的机制,而不仅是当今重要的问题。在这种情况下,新机制可能会在将来发现意外用途,从而节省时间。通用方式似乎与第 3 章中讨论的投资思路一致,在这里您花了更多时间在前面,以节省以后的时间。
另一方面,我们很难预测软件系统的未来需求,因此通用解决方案可能包含从未真正需要的功能。此外,如果您实现的东西过于通用,那么可能无法很好地解决您今天遇到的特定问题。因此,有些人可能会争辩说,最好只关注当今的需求,构建您所知道的需求,并针对您今天打算使用的方式进行专门化处理。如果您采用特殊用途的方式并在以后发现更多用途,则始终可以对其进行重构以使其通用。专用方式似乎与软件开发的增量方式一致。
6.1 使类变得通用
以我的经验,最有效的办法是以某种通用的方式实现新模块。短语“somewhat general-purpose(有点通用)”表示该模块的功能应反映您当前的需求,但其接口则不应该反映您当前的需求。相反,该接口应该足够通用以支持多种用途。该接口应易于使用,以满足当今的需求,而不必专门与它们联系在一起。“有点”这个词很重要:不要忘乎所以,建立一些太过通用的东西,以至于很难满足你当前的需求。
通用方式最重要的(也许是令人惊讶的)好处是,与专用方式相比,它的接口更简单、更深。如果您将该类用于其他目的,则通用方式还可以节省将来的时间。但是,即使该模块仅用于其原始用途,由于其简单性,通用方式仍然更好。
6.2 示例:为编辑器存储文本
让我们考虑一个软件设计课程的示例,其中要求学生构建简单的 GUI 文本编辑器。编辑器必须显示一个文件,并允许用户瞄准,单击并键入以编辑该文件。编辑器必须支持同一文件在不同窗口中的多个同时视图;他们还必须支持文件修改的多级撤销和重做。
每个学生项目都包括一个管理文件的基础文本的类。文本类通常提供以下方法:将文件加载到内存,读取和修改文件的文本以及将修改后的文本写回到文件。
许多学生团队为文本类实现了专用的 API。他们知道该类将在交互式编辑器中被使用,因此他们考虑了编辑器必须提供的功能,并针对这些特定功能定制了文本类的 API。例如,如果编辑者的用户键入了退格键,则编辑者会立即删除光标左侧的字符;如果用户键入删除键,则编辑器立即删除光标右侧的字符。知道这一点后,一些团队在文本类中创建了一个方法来支持以下每个特定功能:
void backspace(Cursor cursor);
void delete(Cursor cursor);这些方法中的每一个都以光标位置作为参数。特殊类型的光标表示此位置。编辑器还必须支持复制或删除选中的区域。学生通过定义选择类并在删除过程中将该类的对象传递给文本类来解决此问题:
void deleteSelection(Selection selection);学生们可能认为,如果文本类的方法与用户可见的功能相对应,则将更易于实现用户界面。但是,实际上,这种专业化对用户界面代码几乎没有好处,并且为使用用户界面或文本类的开发人员带来了很高的认知负担。文本类以大量浅层方法结束,每种浅层方法仅适用于一个用户界面操作。许多方法(例如 delete)仅在单个位置调用。结果,在用户界面上工作的开发人员必须学习大量有关文本类的方法。
这种方式在用户界面和文本类之间造成了信息泄漏。与用户界面有关的抽象(例如选择或退格键)反映在文本类中;这增加了文本类的开发人员的认知负担。每个新的用户界面操作都需要在文本类中定义一个新方法,因此使用该用户界面的开发人员也可能最终也要使用该文本类。类设计的目标之一是允许每个类独立开发,但是专用方式将用户界面和文本类联系在一起。
6.3 更通用的 API
更好的方法是使文本类更通用。仅应根据基本文本功能定义其 API,而不应反映将用其实现的更高级别的操作。例如,只需两种方法即可修改文本:
void insert(Position position, String newText);
void delete(Position start, Position end);第一种方法在文本内的任意位置插入任意字符串,第二种方法删除大于或等于开始但小于结束的位置处的所有字符。此 API 还使用了更通用的 Position 类型来代替 Cursor,它反映了特定的用户界面。文本类还应该提供用于操纵文本中位置的通用工具,例如:
Position changePosition(Position position, int numChars);此方法返回一个新位置,该位置与给定位置相距给定字符数。如果 numChars 参数为正,则新位置在文件中比位置晚;如果 numChars 为负,则新位置在位置之前。必要时,该方法会自动跳到下一行或上一行。使用这些方法,可以使用以下代码来实现删除键(假定 cursor 变量保留当前光标的位置):
text.delete(cursor, text.changePosition(cursor, 1));同样,可以按以下方式实现退格键:
text.delete(text.changePosition(cursor, -1), cursor);使用通用文本 API,实现用户界面功能(如删除和退格)的代码比使用专用文本 API 的原始方法要长一些。但是,新代码比旧代码更容易理解。在用户界面模块工作的开发者很关心退格键会删掉哪些字符。通过新代码,这点一目了然。而旧代码下,开发者必须去阅读文本类的文档或代码,才能明白退格键的作用。而且,采用通用方法比特定方法减少了很多代码,因为它用较少的通用方法代替了文本类中许多特定功能的方法。
使用通用接口实现的文本类,除了可实现交互式编辑器外,还可以用于其他目的。作为一个示例,假设您正在构建一个应用程序,该应用程序通过将所有出现的特定字符串替换为另一个字符串来修改指定文件。专用文本类中的方法(例如,退格键和 Delete)对于此应用程序几乎没有价值。但是,通用文本类已经具有新应用程序所需的大多数功能。缺少的只是一种搜索给定字符串的下一个匹配项的方法,例如:
Position findNext(Position start, String string);当然,交互式文本编辑器可能实现了搜索和替换的机制,在这种情况下,文本类将已经包含此方法。
6.4 通用性可以更好地隐藏信息
通用方法在文本和用户界面类之间提供了更清晰的分隔,从而可以更好地隐藏信息。文本类不需要知道用户界面的详细信息,例如如何处理退格键。这些细节现在封装在用户界面类中。可以添加新的用户界面功能,而无需在文本类中创建新的支持功能。通用界面还减轻了认知负担:使用用户界面的开发人员只需要学习一些简单的方法,就可以将其重复用于各种目的。
文本类原始版本中的 backspace 方法是错误的抽象。它旨在隐藏有关删除哪些字符的信息,但是用户界面模块确实需要知道这一点。用户界面开发人员可能会阅读退格方法的代码,以确认其精确的行为。将方法放在文本类中只会使用户界面开发人员更难获得所需的信息。软件设计最重要的元素之一就是确定谁需要知道什么以及何时知道。当细节很重要时,最好使它们明确且尽可能明显,例如修订的 Backspace 操作实现。将这些信息隐藏在界面后面只会产生晦涩感。
6.5 问自己的问题
识别干净的通用类设计要比创建一个简单。您可以问自己一些问题,这将帮助您在接口的通用和专用之间找到适当的平衡。
满足我当前所有需求的最简单的接口是什么?如果减少 API 中的方法数量而不降低其整体功能,则可能正在创建更多通用的方法。专用文本 API 至少具有三种删除文本的方法:退格,删除和 deleteSelection。通用性更强的 API 只有一种删除文本的方法,可同时满足所有三个目的。仅在每种方法的 API 保持简单的前提下,减少方法的数量才有意义。如果您必须引入许多其他参数以减少方法数量,那么您可能并没有真正简化事情。
在多少情况下会使用此方法?如果一种方法是为特定用途而设计的,例如退格方法,那是一个危险信号,它可能太特殊了。看看是否可以用一个通用方法替换几种专用方法。
这个 API 对我当前的需求来说容易使用吗?这个问题可以帮助你确定什么时候你在让一个 API 变得简单和通用方面走得太远了。如果您必须编写许多其他代码才能将类用于当前用途,那么这是一个危险信号,即该接口未提供正确的功能。例如,针对文本类的一种方式是围绕单字符操作进行设计:insert 插入单个字符 和 delete 删除单个字符。该 API 既简单又通用。但是,对于文本编辑器来说并不是特别容易使用:更高级别的代码将包含许多循环,用于插入或删除字符范围。单字符方法对于大型操作也将是低效的。因此,文本类最好内置对字符范围操作的支持。
6.6 结论
通用接口相比于特定目的的接口有许多优势。它们往往更简单,拥有更少但更深入的方法。它们还提供了类之间的更清晰的分隔,而专用接口则倾向于在类之间泄漏信息。使模块具有某种通用性是降低整体系统复杂性的最佳方法之一。
第 7 章 不同的层,不同的抽象
软件系统由层组成,其中较高的层使用较低层提供的功能。在设计良好的系统中,每一层都提供与其上,下两层不同的抽象。如果您通过调用方法来跟踪一个在层中上下移动的操作,那么抽象会随着每次方法调用而改变。例如:
- 在文件系统中,最上层实现文件抽象。文件由可变长度的字节数组组成,可以通过读写可变长度的字节范围来更新该字节。文件系统的下一层在固定大小的磁盘块的内存中实现了高速缓存。调用者可以假定经常使用的块将保留在内存中,以便可以快速访问它们。最低层由设备驱动程序组成,它们在辅助存储设备和内存之间移动块。
- 在诸如 TCP 的网络传输协议中,最顶层提供的抽象是从一台机器可靠地传递到另一台机器的字节流。这个级别建立在一个较低的级别上,它在机器之间尽最大努力传输有限大小的数据包:大多数数据包会成功传递,但有些数据包可能会丢失或传递顺序错误。
如果系统包含具有相似抽象的相邻层,则这是一个红色标记,表明类分解存在问题。本章讨论了发生这种情况的情况,导致的问题以及如何重构以消除问题。(如果一个系统中相邻的分层,存在了相似的抽象概念,这就表明分类拆解可能存在问题)
7.1 透传方法
当相邻的层具有相似的抽象时,问题通常以透传的形式表现出来。透传是一种除了调用另一个方法(其签名与调用方法的签名相似或相同)之外,很少功能的方法。例如,一个实现 GUI 文本编辑器的学生项目包含一个几乎完全由透传方法组成的类。这是该类的摘录:
public class TextDocument ... {
private TextArea textArea;
private TextDocumentListener listener;
...
public Character getLastTypedCharacter() {
return textArea.getLastTypedCharacter();
}
public int getCursorOffset() {
return textArea.getCursorOffset();
}
public void insertString(String textToInsert, int offset) {
textArea.insertString(textToInsert, offset);
}
public void willInsertString(String stringToInsert, int offset) {
if (listener != null) {
listener.willInsertString(this, stringToInsert, offset);
}
}
...
}该类别中 15 个公共方法中的 13 个是透传方法。
透传方法除了将参数传递给另外一个与其有相同 API 的方法外,不执行任何操作。这通常表示各类之间没有明确的职责划分。
透传方法使类变浅:它们增加了类的接口复杂性,从而增加了复杂性,但是并没有增加系统的整体功能。在上述四个方法中,只有最后一个具有极少的功能,即使有也微乎其微:该方法检查一个变量的有效性。透传方法还会在类之间创建依赖关系:如果针对 TextArea 中的 insertString 方法更改了签名,则必须更改 TextDocument 中的 insertString 方法以进行匹配。
透传方法表明类之间的责任划分存在混淆。在上面的示例中,TextDocument 类提供了 insertString 方法,但是用于插入文本的功能完全在 TextArea 中实现。这通常是一个坏主意:某个功能的接口应该在实现该功能的同一类中。当您看到从一个类到另一个类的透传方法时,请考虑这两个类,并问自己“这些类分别负责哪些功能和抽象?” 您可能会注意到,各类之间的职责重叠。
解决方案是重构类,以使每个类都有各自不同且连贯的职责。图 7.1 说明了几种方法。一种方法,如图 7.1(b)所示,是将较低级别的类直接暴露给较高级别的类的调用者,而从较高级别的类中删除对该功能的所有责任。另一种方法是在类之间重新分配功能,如图 7.1(c)所示。最后,如果无法解开这些类,最好的解决方案可能是如图 7.1(d)所示合并它们。
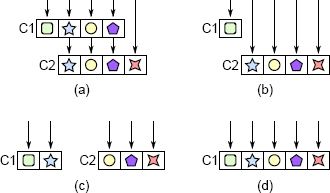
图 7.1:透传方法。在(a)中,类 C1 包含三个透传方法,这些方法只调用 C2 中具有相同签名的方法(每个符号代表一个特定的方法签名)。可以通过使 C1 的调用方像在(b)中那样直接调用 C2,通过在 C1 和 C2 之间重新分配功能以避免在(c)中的类之间进行调用,或者通过组合在(d)中的类来消除透传方法。 。
在上面的示例中,职责交织的三个类为:TextDocument,TextArea 和 TextDocumentListener。学生通过在类之间移动方法并将三个类缩减为两个类来消除透传方法,这两个类的职责更加明确。
7.2 什么时候可以有重复的接口?
具有相同签名的方法并不总是不好的。重要的是,每种新方法都应贡献重要的功能。透传方法很糟糕,因为它们不提供任何新功能。
一个方法调用另一个具有相同签名的方法很有用的例子是调度器。调度器是一种方法,它使用自己的参数从其他几种方法中选择一种来调用;然后,它将其大部分或全部参数传递给选定的方法。调度程序的签名通常与其调用的方法的签名相同。尽管如此,调度程序还是提供了有用的功能:它选择其他几种方法中的哪一种来执行每个任务。
例如,当 Web 服务器从 Web 浏览器接收到传入的 HTTP 请求时,它将调用一个调度器来检查传入请求中的 URL 并选择一种特定的方法来处理该请求。某些 URL 可以通过返回磁盘上文件的内容来处理;其他的则可能通过调用诸如 PHP 或 JavaScript 之类的语言的程序来处理。分发过程可能非常复杂,通常由与传入 URL 匹配的一组规则来驱动。
只要每种方法都提供有用且独特的功能,几种方法都具有相同的签名是可以接受的。调度程序调用的方法具有此属性。另一个示例是具有多种实现方式的接口,例如操作系统中的磁盘驱动程序。每个驱动程序都支持不同类型的磁盘,但是它们都有相同的接口。当几种方法提供同一接口的不同实现时,它将减少认知负担。使用其中一种方法后,与其他方法一起使用会更容易,因为您无需学习新的接口。像这样的方法通常位于同一层,并且它们不会相互调用。
7.3 装饰器
装饰器设计模式(也称为“包装器”)是一种鼓励跨层复制 API 的模式。装饰对象接受现有对象并扩展其功能;它提供一个与底层对象相似或相同的 API,它的方法调用底层对象的方法。在第 4 章的 Java I/O 示例中,BufferedInputStream 类是一个装饰器:给定一个 InputStream 对象,它提供了相同的 API,但是引入了缓冲。例如,当它的 read 方法被调用来读取单个字符时,它会调用底层 InputStream 上的 read 来读取更大的块,并保存额外的字符来满足未来的 read 调用。另一个例子出现在窗口系统中:Window 类实现了一个不能滚动的窗口的简单形式,而 ScrollableWindow 类通过添加水平和垂直滚动条来装饰窗口类。
装饰器的动机是将类的专用扩展与更通用的核心分开。但是,装饰器类往往很浅:它们引入了大量的样板,以实现少量的新功能。装饰器类通常包含许多透传方法。过度使用装饰器模式很容易,为每个小的新功能创建一个新类。这导致诸如 Java I/O 示例之类的浅层类激增。
创建装饰器类之前,请考虑以下替代方法:
- 您能否将新功能直接添加到基础类,而不是创建装饰器类?如果新功能是相对通用的,或者在逻辑上与基础类相关,或者如果基础类的大多数使用也将使用新功能,则这是有意义的。例如,几乎每个创建 Java InputStream 的人都会创建一个 BufferedInputStream,并且缓冲是 I/O 的自然组成部分,因此应该合并这些类。
- 如果新功能专用于特定用例,将其与用例合并而不是创建单独的类是否有意义?
- 您可以将新功能与现有的装饰器合并,而不是创建新的装饰器吗?这将产生一个更深的装饰器类,而不是多个浅的装饰器类。
- 最后,问问自己新功能是否真的需要包装现有功能:是否可以将其实现为独立于基类的独立类?在窗口示例中,滚动条可能与主窗口分开实现,而无需包装其所有现有功能。
有时装饰者很有意义,但通常有更好的选择。
7.4 接口与实现
“不同层,不同抽象”规则的另一个应用是,类的接口通常应与其实现不同:内部使用的表示形式应与接口中出现的抽象形式不同。如果两者具有相似的抽象,则该类可能不是很深。例如,在第 6 章讨论的文本编辑器项目中,大多数团队都以文本行的形式实现了文本模块,每行分别存储。一些团队还使用 getLine 和 putLine 之类的方法围绕行设计了文本类的 API。但是,这使文本类使用起来较浅且笨拙。在较高级别的用户界面代码中,通常在行中间插入文本(例如,当用户键入内容时)或删除跨行的文本范围。通过用于文本类的面向行的 API,调用者被迫拆分和合并行以实现用户界面操作。这段代码很简单,并且在用户界面的实现中被复制和散布。
文本类提供面向字符的接口时,使用起来要容易得多,例如,insert 方法可在文本的任意位置插入任意文本字符串(可能包括换行符),而 delete 方法则删除文本在文本中的两个任意位置之间。在内部,文本仍以行表示。面向字符的接口封装了文本类内部的行拆分和连接的复杂性,这使文本类更深,并简化了使用该类的高级代码。通过这种方法,文本 API 与面向行的存储机制大不相同。差异表示该类提供的有价值的功能。
7.5 传递变量
跨层 API 重复的另一种形式是传递变量,该变量是通过一长串方法向下传递的变量。图 7.2(a)显示了数据中心服务的示例。命令行参数描述用于安全通信的证书。只有底层方法 m3 才需要此信息,该方法调用一个库方法来打开套接字,但是该信息会通过 main 和 m3 之间路径上的所有方法向下传递。cert 变量出现在每个中间方法的签名中。
传递变量增加了复杂性,因为它们强制所有中间方法知道它们的存在,即使这些方法对变量没有用处。此外,如果存在一个新变量(例如,最初构建的系统不支持证书,但是您后来决定添加该支持),则可能必须修改大量的接口和方法才能将变量传递给所有相关路径。
消除传递变量可能具有挑战性。一种方法是查看最顶层和最底层方法之间是否已共享对象。在图 7.2 的数据中心服务示例中,也许存在一个对象,其中包含有关网络通信的其他信息,这对于 main 和 m3 都是可用的。如果是这样,main 可以将证书信息存储在该对象中,因此不必通过通往 m3 的路径上的所有干预方法来传递证书(请参见图 7.2(b))。但是,如果存在这样的对象,则它本身可能是传递变量(m3 还将如何访问它?)。
另一种方法是将信息存储在全局变量中,如图 7.2(c)所示。这避免了将信息从一个方法传递到另一个方法的需要,但是全局变量几乎总是会产生其他问题。例如,全局变量使得不可能在同一过程中创建同一系统的两个独立实例,因为对全局变量的访问会发生冲突。在生产中似乎不太可能需要多个实例,但是它们通常在测试中很有用。
我最常使用的解决方案是引入一个上下文对象,如图 7.2(d)所示。上下文存储应用程序的所有全局状态(否则将是传递变量或全局变量的任何状态)。大多数应用程序在其全局状态下具有多个变量,这些变量表示诸如配置选项,共享子系统和性能计数器之类的内容。每个系统实例只有一个上下文对象。上下文允许系统的多个实例在单个进程中共存,每个实例都有自己的上下文。
不幸的是,在许多地方可能都需要上下文,因此它有可能成为传递变量。为了减少必须意识到的方法数量,可以将上下文的引用保存在系统的大多数主要对象中。在图 7.2(d)的示例中,包含 m3 的类将对上下文的引用作为实例变量存储在其对象中。创建新对象时,创建方法将从其对象中检索上下文引用,并将其传递给新对象的构造函数。使用这种方法,上下文随处可见,但在构造函数中仅作为显式参数出现。
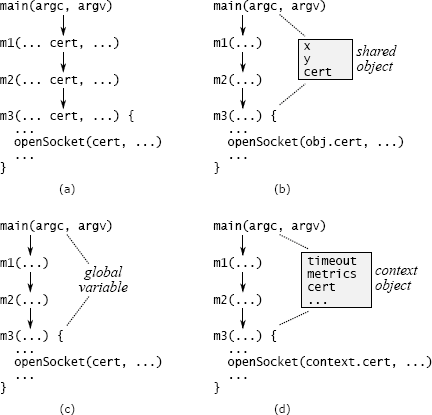
图 7.2:处理传递变量的可能技术。在(a)中,证书通过方法 m1 和 m2 传递,即使它们不使用它也是如此。在(b)中,main 和 m3 具有对一个对象的共享访问权,因此可以将变量存储在此处,而不用将其传递给 m1 和 m2。在(c)中,cert 存储为全局变量。在(d)中,证书与其他系统范围的信息(例如超时值和性能计数器)一起存储在上下文对象中;对上下文的引用存储在其方法需要访问它的所有对象中。
上下文对象统一了所有系统全局信息的处理,并且不需要传递变量。如果需要添加新变量,则可以将其添加到上下文对象;除了上下文的构造函数和析构函数外,现有代码均不受影响。由于上下文全部存储在一个位置,因此上下文可以轻松识别和管理系统的全局状态。上下文也便于测试:测试代码可以通过修改上下文中的字段来更改应用程序的全局配置。如果系统使用传递变量,则实施此类更改将更加困难。
上下文远非理想的解决方案。存储在上下文中的变量具有全局变量的大多数缺点。例如,为什么存在特定变量或在何处使用特定变量可能并不明显。没有纪律,上下文会变成巨大的数据抓包,从而在整个系统中创建不明显的依赖关系。上下文也可能产生线程安全问题;避免问题的最佳方法是使上下文中的变量不可变。不幸的是,我没有找到比上下文更好的解决方案。
7.6 结论
添加到系统中的每一个设计基础设施,如接口、参数、函数、类或定义,都会增加复杂性,因为开发人员必须了解这个元素。为了使一个元素提供对抗复杂性的净增益,它必须消除在没有设计元素的情况下出现的一些复杂性。否则,您最好在没有该特定元素的情况下实现该系统。例如,一个类可以通过封装功能来降低复杂性,这样该类的用户就不必知道它了。
“不同的层,不同的抽象”规则只是此思想的一种应用:如果不同的层具有相同的抽象,例如透传方法或装饰器,则很有可能它们没有提供足够的利益来补偿它们代表的其他基础结构。类似地,传递参数要求几种方法中的每一种都知道它们的存在(这增加了复杂性),而又不提供其他功能。
第 8 章 降低复杂性
本章介绍了有关如何创建更深层类的另一种思考方式。假设您正在开发一个新模块,并且发现了一个不可避免的复杂性。哪个更好:应该让模块的使用者处理复杂性,还是应该在模块内部处理复杂性?如果复杂度与模块提供的功能有关,则第二个答案通常是正确的答案。大多数模块拥有的使用者多于开发人员,因此麻烦开发人员比麻烦使用者更好。作为模块开发人员,您应该努力使模块使用者的生活尽可能轻松,即使这对您来说意味着额外的工作。表达此想法的另一种方法是,模块具有简单的接口比简单的实现更为重要。
作为开发人员,很容易以相反的方式行事:解决简单的问题,然后将困难的问题推给其他人。如果出现不确定如何处理的条件,最简单的方法是抛出异常并让调用者处理它。如果不确定要实施什么策略,则可以定义一些配置参数来控制该策略,然后由系统管理员自行确定最佳策略。
这样的方法短期内会使您的生活更轻松,但它们会加剧复杂性,因此许多人必须处理一个问题,而不仅仅是一个人。例如,如果一个类抛出异常,则该类的每个调用者都必须处理该异常。如果一个类导出配置参数,则每个系统管理员在每次安装中都必须学习如何设置它们。
8.1 示例:编辑器文本类
考虑为 GUI 文本编辑器管理文件文本的类,这在第 6 章和第 7 章中讨论过。该类提供了将文件从磁盘读入内存、查询和修改文件在内存中的副本以及将修改后的版本写回磁盘的方法。当学生必须实现这个类时,他们中的许多人选择了一个面向行的接口,该接口具有读取、插入和删除整行文本的方法。这导致了类实现起来很简单,但也为更高级别的软件带来了复杂性。在用户界面级别,操作很少涉及整行操作。例如,击键会导致在现有行中插入单个字符;复制或删除选择项可以修改几个不同行的部分。使用面向行的文本接口,为了实现用户界面,高级软件必须分割和连接行。
面向字符的界面(如 6.3 节中所述)降低了复杂性。用户界面软件现在可以插入和删除任意范围的文本,而无需分割和合并行,因此变得更加简单。文本类的实现可能会变得更加复杂:如果内部将文本表示为行的集合,则必须拆分和合并行以实现面向字符的操作。这种方法更好,因为它封装了在文本类中拆分和合并的复杂性,从而降低了系统的整体复杂性。
8.2 示例:配置参数
配置参数是提高复杂度而不是降低复杂度的一个示例。类可以在内部输出一些控制其行为的参数,而不是在内部确定特定的行为,例如高速缓存的大小或在放弃之前重试请求的次数。然后,该类的使用者必须为参数指定适当的值。在当今的系统中,配置参数已变得非常流行。有些系统有数百个。
拥护者认为配置参数不错,因为它们允许用户根据他们的特定要求和工作负载来调整系统。在某些情况下,低级基础结构代码很难知道要应用的最佳策略,而用户则对其领域更加熟悉。例如,用户可能知道某些请求比其他请求更紧迫,因此用户为这些请求指定更高的优先级是有意义的。在这种情况下,配置参数可以在更广泛的领域中带来更好的性能。
但是,配置参数还提供了一个轻松的借口,可以避免处理重要问题并将其传递给其他人。在许多情况下,用户或管理员很难或无法确定参数的正确值。在其他情况下,可以通过在系统实现中进行一些额外的工作来自动确定正确的值。考虑必须处理丢失数据包的网络协议。如果它发送请求但在一定时间内未收到响应,则重新发送该请求。确定重试间隔的一种方法是引入配置参数。但是,传输协议可以通过测量成功请求的响应时间,然后将其倍数用于重试间隔,自己计算出一个合理的值。这种方法降低了复杂性,使用户不必找出正确的重试间隔。它具有动态计算重试间隔的其他优点,因此,如果操作条件发生变化,它将自动进行调整。相反,配置参数很容易过时。
因此,您应尽可能避免使用配置参数。在导出配置参数之前,请问自己:“用户(或更高级别的模块)是否能够确定比我们在此确定的更好的值?” 当您创建配置参数时,请查看是否可以自动计算合理的默认值,因此用户仅需在特殊情况下提供值即可。理想情况下,每个模块都应完全解决问题。配置参数导致解决方案不完整,从而增加了系统复杂性。
8.3 走得太远
降低复杂性时要谨慎处理;这个想法很容易做过头。一种极端的方法是将整个应用程序的所有功能归为一个类,这显然没有意义。如果(a)被降低的复杂度与该类的现有功能密切相关,(b)降低复杂度将导致应用程序中其他地方的许多简化,则降低复杂度最有意义。简化了类的接口。请记住,目标是最大程度地降低整体系统复杂性。
第 6 章介绍了一些学生如何在文本类中定义反映用户界面的方法,例如实现退格键功能的方法。这似乎很好,因为它可以降低复杂性。但是,将用户界面的知识添加到文本类中并不会大大简化高层代码,并且用户界面的知识与文本类的核心功能无关。在这种情况下,降低复杂度只会导致信息泄漏。
8.4 结论
在开发模块时,为了减少用户的痛苦,要找机会给自己多吃一点苦。
第 9 章 在一起更好还是分开更好?
软件设计中最基本的问题之一是:给定两个功能,它们应该在同一位置一起实现,还是应该分开实现?这个问题适用于系统中的所有级别,例如功能,方法,类和服务。例如,应该在提供面向流的文件 I/O 的类中包括缓冲,还是应该在单独的类中?HTTP 请求的解析应该完全在一个方法中实现,还是应该在多个方法(甚至多个类)之间划分?本章讨论做出这些决定时要考虑的因素。这些因素中的一些已经在前面的章节中进行了讨论,但是为了完整起见,这里将对其进行重新讨论。
在决定是合并还是分开时,目标是降低整个系统的复杂性并改善其模块化。看来实现此目标的最佳方法是将系统划分为大量的小组件:组件越小,每个单独的组件可能越简单。但是,细分的行为会带来额外的复杂性,而这在细分之前是不存在的:
- 一些组件的复杂性仅来自组件的数量:组件越多,就越难以追踪所有组件,也就越难在大型集合中找到所需的组件。细分通常会导致更多接口,并且每个新接口都会增加复杂性。
- 细分可能会导致附加代码来管理组件。例如,在细分之前使用单个对象的一段代码现在可能必须管理多个对象。
- 细分产生分离:细分后的组件将比细分前的组件相距更远。例如,在细分之前位于单个类中的方法可能在细分之后位于不同的类中,并且可能在不同的文件中。分离使开发人员更难于同时查看这些组件,甚至很难知道它们的存在。如果组件真正独立,那么分离是好的:它使开发人员可以一次专注于单个组件,而不会被其他组件分散注意力。另一方面,如果组件之间存在依赖性,则分离是不好的:开发人员最终将在组件之间来回翻转。更糟糕的是,他们可能不了解依赖关系,这可能导致错误。
- 细分可能导致重复:细分之前的单个实例中存在的代码可能需要存在于每个细分的组件中。
如果它们紧密相关,则将代码段组合在一起是最有益的。如果各部分无关,则最好分开。以下是两个代码相关的一些提示:
- 他们共享信息;例如,这两段代码都可能取决于特定类型文档的语法。
- 它们一起使用:任何使用其中一段代码的人都可能同时使用另一段代码。这种关系形式只有在双向关系中才具有吸引力。作为反例,磁盘块高速缓存几乎总是包含哈希表,但是哈希表可以在许多不涉及块高速缓存的情况下使用。因此,这些模块应该分开。
- 它们在概念上重叠,因为存在一个简单的更高级别的类别,其中包括这两段代码。例如,搜索子字符串和大小写转换都属于字符串操作类别。流控制和可靠的交付都属于网络通信的范畴。
- 不看其中的一段代码就很难理解。
本章的其余部分使用更具体的规则以及示例来说明何时将代码段组合在一起以及何时将它们分开是有意义的。
9.1 如果信息共享则汇聚在一起
5.4 节在实现 HTTP 服务器的项目上下文中介绍了此原则。在其第一个实现中,该项目使用了两个位于不同类的方法来读取和解析 HTTP 请求。第一个方法从网络套接字读取传入请求的文本,并将其放置在字符串对象中。第二个方法解析字符串以提取请求的各个组成部分。经过这种分解,这两种方法最终都对 HTTP 请求的格式有了相当的了解:第一个方法只是尝试读取请求,而不是解析请求,但是如果不执行大多数操作,就无法确定请求的结束解析它的工作(例如,它必须解析标头行才能识别包含整个请求长度的标头)。由于此共享信息,最好在同一位置读取和解析请求;当两个类合而为一时,代码变得更短,更简单。
9.2 如果可以简化接口则汇集在一起
当两个或多个模块组合成一个模块时,可以为新模块定义一个比原始接口更简单或更易于使用的接口。当原始模块各自实现问题解决方案的一部分时,通常会发生这种情况。在上一部分的 HTTP 服务器示例中,原始方法需要一个接口来从第一个方法返回 HTTP 请求字符串并将其传递给第二个方法。当这些方法结合在一起时,这些接口就被淘汰了。
另外,将两个或更多类的功能组合在一起时,可能会自动执行某些功能,因此大多数用户无需了解它们。Java I/O 库说明了这种机会。如果将 FileInputStream 和 BufferedInputStream 类组合在一起,并且默认情况下提供了缓冲,则绝大多数用户甚至都不需要知道缓冲的存在。组合后的 FileInputStream 类可能提供禁用或替换默认缓冲机制的方法,但是大多数用户不需要了解它们。
9.3 消除重复
如果发现反复重复的代码模式,请查看是否可以重新组织代码以消除重复。一种方法是将重复的代码分解为一个单独的方法,并用对该方法的调用替换重复的代码段。如果重复的代码段很长并且用来替换方法具有简单的签名,则此方法最有效。如果代码段只有一两行,那么用方法调用替换它可能不会有太多好处。如果代码段与其环境以复杂的方式进行交互(例如,通过访问多个局部变量),则替换方法可能需要复杂的签名(例如,许多“按引用传递”参数),这会降低其价值。
消除重复的另一种方法是重构代码,使相关代码段仅需要在一个地方执行。假设您正在编写一种方法,该方法需要在几个不同的点返回错误,并且在返回之前需要在每个这些点执行相同的清除操作(示例请参见图 9.1)。如果编程语言支持 goto,则可以将清除代码移到方法的最后,然后在需要返回错误的每个点处转到该片段,如图 9.2 所示。Goto 语句通常被认为是一个坏主意,如果不加选择地使用它们,可能会导致无法识别的代码,但是在诸如此类的情况下,它们可用于从嵌套代码中脱离,因此它们非常有用。
9.4 单独的通用代码和专用代码
如果模块包含可用于多种不同目的的机制,则它应仅提供一种通用机制。它不应包含专门针对特定用途的机制的代码,也不应包含其他通用机制。与通用机制关联的专用代码通常应放在不同的模块中(通常是与特定用途关联的模块)。第 6 章中的 GUI 编辑器讨论阐明了这一原则:最佳设计是文本类提供通用文本操作,而特定于用户界面的操作(例如删除所选内容)则在用户界面模块中实现。这种方法消除了早期设计中存在的信息泄漏和附加接口,在早期设计中,专门的用户界面操作是在文本类中实现的。
如果相同的代码(或几乎相同的代码)一遍又一遍地出现,那是一个危险信号,您没有找到正确的抽象。
switch (common->opcode) {
case DATA: {
DataHeader* header = received->getStart<DataHeader>();
if (header == NULL) {
LOG(WARNING, "%s packet from %s too short (%u bytes)",
opcodeSymbol(common->opcode),
received->sender->toString(),
received->len);
return;
}
}
case GRANT: {
GrantHeader* header = received->getStart<GrantHeader>();
if (header == NULL) {
LOG(WARNING, "%s packet from %s too short (%u bytes)",
opcodeSymbol(common->opcode),
received->sender->toString(),
received->len);
return;
}
}
...
case RESEND: {
ResendHeader* header = received->getStart<ResendHeader>();
if (header == NULL) {
LOG(WARNING, "%s packet from %s too short (%u bytes)",
opcodeSymbol(common->opcode),
received->sender->toString(),
received->len);
return;
}
}
...
}图 9.1:此代码处理不同类型的传入网络数据包。对于每种类型,如果数据包对于该类型而言太短,则会记录一条消息。在此版本的代码中,LOG 语句对于几种不同的数据包类型是重复的。
switch (common->opcode) {
case DATA: {
DataHeader* header = received->getStart<DataHeader>();
if (header == NULL)
goto packetTooShort;
...
}
case GRANT: {
GrantHeader* header = received->getStart<GrantHeader>();
if (header == NULL)
goto packetTooShort;
...
}
case RESEND: {
ResendHeader* header = received->getStart<ResendHeader>();
if (header == NULL)
goto packetTooShort;
...
}
}
...
packetTooShort:
LOG(WARNING, "%s packet from %s too short (%u bytes)",
opcodeSymbol(common->opcode),
received->sender->toString(),
received->len);
return;图 9.2:对图 9.1 中的代码进行了重新组织,因此只有 LOG 语句的一个副本。
通常,系统的下层倾向于更通用,而上层则更专用。例如,应用程序的最顶层包含完全特定于该应用程序的功能。将专用代码与通用代码分开的方法是将专用代码向上拉到较高的层,而将较低的层保留为通用。当您遇到同时包含通用功能和专用功能的同一类的类时,请查看该类是否可以分为两个类,一个包含通用功能,另一个在其上分层以提供特殊功能
9.5 示例:插入光标和选择
下一节将通过三个示例说明上述原则。在两个示例中,最好的方法是分离相关的代码段。在第三个示例中,最好将它们结合在一起。
第一个示例由插入光标和第 6 章的 GUI 编辑器项目中的选择组成。编辑器显示闪烁的垂直线,指示用户键入的文本将出现在文档中的何处。它还显示了一个突出显示的字符范围,称为选择,用于复制或删除文本。插入光标始终可见,但是有时可能没有选择文本。如果存在选择,则插入光标始终位于其一端。
选择和插入光标在某些方面相关。例如,光标始终位于所选内容的一端,并且倾向于将光标和所选内容一起操作:单击并拖动鼠标将它们都设置,然后插入文本会首先删除所选的文本(如果有),然后在光标位置插入新文本。因此,使用单个对象管理选择和光标似乎合乎逻辑,并且一个项目团队采用了这种方法。该对象在文件中存储了两个位置,以及布尔值,它们指示光标的哪一端以及选择是否存在。
但是,合并的对象很尴尬。它对高级代码没有任何好处,因为高级代码仍然需要将选择和游标视为不同的实体,并且对它们进行单独操作(在插入文本期间,它首先在组合对象上调用一个方法来删除选定的文本;然后调用另一个方法来检索光标位置,以插入新文本)。实际上,组合对象比单独的对象实现起来要复杂得多。它避免了将光标位置存储为单独的实体,而是不得不存储一个布尔值,该布尔值指示选择的哪一端是光标。为了检索光标位置,组合对象必须首先测试布尔值,然后选择选择的适当结尾。
当通用机制还包含专门用于该机制的特定用途的代码时,就会出现此红色标志。这使该机制更加复杂,并在该机制与特定用例之间造成了信息泄漏:对用例的未来修改也可能需要对基础机制进行更改。
在这种情况下,选择和光标之间的关联度不足以将它们组合在一起。当修改代码以分隔选择和光标时,用法和实现都变得更加简单。与必须从中提取选择和光标信息的组合对象相比,单独的对象提供了更简单的接口。游标的实现也变得更加简单,因为游标的位置是直接表示的,而不是通过选择和布尔值间接表示的。实际上,在修订版中,没有特殊的类用于选择或游标。相反,引入了一个新的 Position 类来表示文件中的位置(行号和行内的字符)。选择用两个位置表示,光标用一个位置表示。Position 类还在项目中找到了其他用途。这个例子也展示了第 6 章讨论过的一个更低级但更通用的接口的好处。
9.6 示例:单独的日志记录类
第二个示例涉及学生项目中的关于记录错误日志的部分。一个类包含几个代码序列,如下所示:
try {
rpcConn = connectionPool.getConnection(dest);
} catch (IOException e) {
NetworkErrorLogger.logRpcOpenError(req, dest, e);
return null;
}不是在检测到错误时记录错误日志,而是调用特殊错误日志记录类中的单独方法。错误记录类是在同一源文件的末尾定义的:
private static class NetworkErrorLogger {
/**
* Output information relevant to an error that occurs when trying
* to open a connection to send an RPC.
*
* @param req
* The RPC request that would have been sent through the connection
* @param dest
* The destination of the RPC
* @param e
* The caught error
*/
public static void logRpcOpenError(RpcRequest req, AddrPortTuple dest, Exception e) {
logger.log(Level.WARNING, "Cannot send message: " + req + ". \n" + "Unable to find or open connection to " + dest + " :" + e);
}
...
}NetworkErrorLogger 类包含几个方法,例如 logRpcSendError 和 logRpcReceiveError,每个方法都记录了不同类型的错误。
这种分离除了增加了复杂性,没有任何好处。日志记录方法很浅:大多数只包含一行代码,但是它们需要大量的文档。每个方法仅在单个位置调用。日志记录方法高度依赖于它们的调用方:读取调用方的人很可能会切换到日志记录方法,以确保记录了正确的信息。同样,阅读日志记录方法的人可能会转到调用方以了解该方法的目的。
在此示例中,最好删除日志记录方法,并将日志记录语句放置在检测到错误的位置。这将使代码更易于阅读,并消除了日志记录方法所需的接口。
9.7 示例:编辑器撤消机制
在 6.2 节的 GUI 编辑器项目中,要求之一是支持多个层面上的撤消/重做,不仅是文本的改动,还有选择、插入光标、和视图的改动。例如,如果用户选择了一些文本,将其删除,滚动到文件中的其他位置,然后调用 undo,则编辑器必须将其状态恢复为删除前的状态。这包括还原已删除的文本,再次选择它,并使所选的文本在窗口中可见。
一些学生项目将整个撤消机制实现为文本类的一部分。文本类维护所有不可撤消更改的列表。每当更改文本时,它将自动将条目添加到此列表中。对于选择、插入光标和视图的更改,用户界面代码调用文本类中的其他方法,然后将这些更改的条目添加到撤消列表中。当用户请求撤消或重做时,用户界面代码将调用文本类中的方法,该方法然后处理撤消列表中的条目。对于与文本相关的条目,它更新了文本类的内部。对于与其他事物(例如选择)相关的条目,文本类调用用户界面代码来执行撤销或重做。
这种方法在文本类中导致了一系列尴尬的功能。撤消/重做的核心功能由通用机制组成,用于管理已执行的动作列表,并在撤消和重做操作期间逐步执行这些动作。核心功能与专用处理程序一起位于 text 类中,该专用处理程序对诸如文本和选择之类的特定内容实现了撤消和重做。用于选择和光标的专用撤消处理程序与文本类中的任何其他内容均无关。它们导致文本类和用户界面之间的信息泄漏,以及每个模块中来回传递撤消信息的额外方法。如果将来将新的可撤消实体添加到系统中,则将需要更改文本类,包括特定于该实体的新方法。此外,通用的撤销核心功能与类中的通用文本功能关系不大。
通过提取撤消/重做机制的通用核心功能并将其放在单独的类中,可以解决这些问题:
public class History {
public interface Action {
public void redo();
public void undo();
}
History() {...}
void addAction(Action action) {...}
void addFence() {...}
void undo() {...}
void redo() {...}
}在此设计中,History 类管理实现接口 History.Action 的对象的集合。每个 History.Action 描述一个操作,例如插入文本或更改光标位置,并且它提供了可以撤消或重做该操作的方法。History 类对操作中存储的信息或它们如何实现其撤消和重做方法一无所知。History 类维护一个历史记录列表,该列表描述了应用程序生命周期内执行的所有操作,它还提供了撤消和重做方法,这些方法响应用户请求的撤消和重做,在 History.Actions 中调用撤消和重做方法。
History.Actions 是特殊目的的对象:每个人都了解一种特殊的可撤销操作。它们在 History 类之外的模块中实现,这些模块可以理解特定类型的可撤销操作。文本类可能实现 UndoableInsert 和 UndoableDelete 对象,以描述文本的插入和删除。每当插入文本时,文本类都会创建一个描述该插入的新 UndoableInsert 对象,并调用 History.addAction 将其添加到历史列表中。编辑器的用户界面代码可能会创建 UndoableSelection 和 UndoableCursor 对象,这些对象描述对选择和插入光标的更改。
History 类还允许对操作进行分组,例如,来自用户的单个撤消请求可以恢复已删除的文本,重新选择已删除的文本以及重新放置插入光标。有多种将动作分组的方法。历史类使用栅栏,栅栏是放置在历史列表中的标记,用于分隔相关动作的组。每次对 History.redo 的调用都会向后浏览历史记录列表,撤消操作,直到到达下一个栅栏。围栏的位置由更高级别的代码通过调用 History.addFence 确定。
这种方法将撤消功能分为三类,每类都在不同的地方实现:
一种用于管理和分组动作以及调用撤消/重做操作的通用机制(由 History 类实现)。特定操作的细节(由各种类实现,每个类都了解少量的操作类型)。分组操作的策略(由高级用户界面代码实现,以提供正确的整体应用程序行为)。这些类别中的每一个都可以在不了解其他类别的情况下实施。History 类不知道要撤消哪种操作;它可以用于多种应用。每个 Action 类仅理解一种动作,并且 History 类和 Action 类都不需要知道将动作分组的策略。
关键的设计决策是将撤消机制的通用部分与专用部分分开,然后将通用部分单独放在一个类中。一旦完成,其余的设计就自然而然的出现了。
注意:将通用代码与专用代码分离的建议是指与特定机制相关的代码。例如,特殊用途的撤消代码(例如撤消文本插入的代码)应该与通用用途的撤消代码(例如管理历史记录列表的代码)分开。然而,将一种机制的专用代码与另一种机制的通用代码组合起来通常是有意义的。text 类就是这样一个例子:它实现了一种管理文本的通用机制,但是它包含了与撤销相关的专用代码。撤消代码是专用的,因为它只处理文本修改的撤消操作。将这段代码与 History 类中通用的 undo 基础结构结合在一起是没有意义的,但是将它放在 text 类中是有意义的,因为它与其他文本函数密切相关。
9.8 拆分和合并方法
何时细分的问题不仅适用于类,而且还适用于方法:是否有时最好将现有方法分为多个较小的方法?还是应该将两种较小的方法合并为一种较大的方法?长方法比短方法更难于理解,因此许多人认为仅长度是分解方法的一个很好的理由。课堂上的学生通常会获得严格的标准,例如“拆分超过 20 行的任何方法!”
但是,长度本身很少是拆分方法的一个很好的理由。通常,开发人员倾向于过多地分解方法。拆分方法会引入其他接口,从而增加了复杂性。它还将原始方法的各个部分分开,如果这些部分实际上是相关的,则使代码更难阅读。您不应该分解一种方法,除非它使整个系统更加简单;我将在下面讨论这种情况。
长方法并不总是坏的。例如,假设一个方法包含按顺序执行的五个 20 行代码块。如果这些块是相对独立的,则可以一次读取并理解该方法的一个块。将每个块移动到单独的方法中并没有太大的好处。如果这些块具有复杂的交互作用,则将它们保持在一起就显得尤为重要,这样读者就可以一次看到所有代码。如果每个块使用单独的方法,则读者将不得不在这些扩展方法之间来回切换,以了解它们如何协同工作。如果方法具有简单的签名并且易于阅读,则包含数百行代码的方法是可以接受的。这些方法很深(功能多,接口简单),很好。
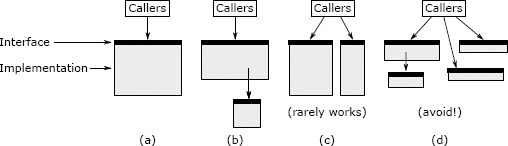
图 9.3:方法(a)可以通过提取子任务(b)或将其功能划分为两个单独的方法(c)进行拆分。如果方法导致浅方法,则不应拆分该方法,如(d)所示。
设计方法时,最重要的目标是提供简洁的抽象。每种方法都应该做一件事并且完全做的彻底。该方法应该具有简洁的接口,以便用户无需费神就可以正确使用它。该方法应该很深:其接口应该比其实现简单得多。如果一个方法具有所有这些属性,那么它的长短与否无关紧要。
总体而言,分割一个方法只有在产生更清晰的抽象时才有意义。有两种方式可以做到这一点,如图 9.3 所示。最佳方法是将子任务分解为单独的方法,如图 9.3(b)所示。该细分产生一个包含该子任务的子方法和一个包含原始方法其余部分的父方法;父方法调用子字方法。新的父方法的接口与原始方法的接口相同。如果存在一个与原始方法的其余部分完全可分离的子任务,则这种细分形式是有意义的,这意味着(a)读取子方法的某人不需要了解有关父方法的任何信息,以及(b)某人在阅读父方法不需要了解子方法的实现。通常,这意味着子方法是相对通用的:可以想象除父方法外,其他方法也可以使用它。如果您做了这种形式进行拆分,然后发现自己在父方法和子方法之间来回跳转以了解他们如何一起工作,那是一个警告(“联合方法”),表明拆分可能不是一个好主意。
分解方法的第二种方法是将其拆分为两个单独的方法,每个方法对原始方法的调用者都可见,如图 9.3(c)所示。如果原始方法的接口过于复杂,这是有道理的,因为该接口试图执行不密切相关的多项操作。在这种情况下,可以将方法的功能划分为两个或更多个较小的方法,每个方法仅具有原始方法功能的一部分。如果进行这样的拆分,则每个子方法的接口应该比原始方法的接口更简单。理想情况下,大多数调用者只需要调用两个新方法之一即可;如果调用者必须同时调用这两个新方法,则将增加复杂性,从而降低拆分是个好主意的可能性。新方法将更加专注于它们的工作。如果新方法比原始方法更具通用性,那么这是一个好兆头(例如,您可以想象在其他情况下单独使用它们)。
图 9.3(c)所示形式的拆分并不是很有意义,因为它们导致调用者不得不处理多个方法而不是一个方法。当您以这种方式拆分时,您可能会遇到几种浅层方法的风险,如图 9.3(d)所示。如果调用者必须调用每个单独的方法,并在它们之间来回传递状态,则拆分不是一个好主意。如果您正在考虑像图 9.3(c)所示的拆分,则应基于它是否简化了调用者的情况来进行判断。
在某些情况下,通过将方法结合在一起可以简化系统。例如,连接方法可以用一种更深的方法代替两种浅的方法。它可以消除重复的代码;它可以消除原始方法或中间数据结构之间的依赖关系;它可能导致更好的封装,从而使以前在多个位置存在的知识现在被隔离在一个位置;也可能会使接口更简单,如 9.2 节所述。
应该可以独立理解每种方法。如果您不能不理解另一种方法的实现而导致无法理解一种方法的实现,那就是一个危险信号。该危险信号也可以在其他情况下发生:如果两段代码在物理上是分开的,但是只有通过查看另一段代码才能理解它们,这就是危险信号。
9.9 结论
拆分或合并模块的决定应基于复杂性。选择一种结构,它可以最好的隐藏信息,产生最少的依赖关系和最深的接口。
第 10 章 通过定义规避错误
异常处理是软件系统中最糟糕的复杂性来源之一。处理特殊情况的代码在本质上比处理正常情况的代码更难编写,并且开发人员经常在定义异常时不考虑异常的处理方式。本章讨论了为什么异常对复杂性的贡献不成比例,然后说明了如何简化异常处理。本章总的主要教训是减少必须处理异常的地方的数量。在许多情况下,可以修改操作的语义,以便正常行为可以处理所有情况,并且没有要报告的特殊条件(这就是本章的主题)。
10.1 为什么异常会增加复杂性
我使用“异常”一词来指代任何会改变程序中正常控制流程的不常见条件。许多编程语言都包含一种正式的异常机制,该机制允许异常由低级代码引发并由捕获代码(try catch)捕获。但是,即使不使用正式的异常报告机制,异常也可能发生,例如,当某个方法返回一个特殊值指示其未完成其正常行为时。所有这些形式的异常都会增加复杂性。
一段特定的代码可能会以几种不同的方式遇到异常:
- 调用方可能会提供错误的参数或配置信息。
- 调用的方法可能无法完成请求的操作。例如,I/O 操作可能失败,或者所需的资源可能不可用。
- 在分布式系统中,网络数据包可能会丢失或延迟,服务器可能无法及时响应,或者节点间可能会以意想不到的方式进行通信。
- 该代码可能会检测到错误,内部不一致或未准备处理的情况。
大型系统必须应对许多特殊情况,特别是在它们是分布式的或需要容错的情况下。异常处理可以占系统中所有代码的很大一部分。
异常处理代码天生就比正常情况下的代码更难写。异常中断了正常的代码流;它通常意味着某事没有像预期的那样工作。当异常发生时,程序员可以用两种方法处理它,每种方法都很复杂。第一种方法是向前推进并完成正在进行的工作,尽管存在例外。例如,如果一个网络数据包丢失,它可以被重发;如果数据损坏了,也许可以从冗余副本中恢复数据。第二种方法是中止正在进行的操作,向上报告异常。但是,中止可能很复杂,因为异常可能发生在系统状态不一致的地方(数据结构可能已经部分初始化);异常处理代码必须恢复一致性,例如通过撤销发生异常之前所做的任何更改。
此外,异常处理代码为更多异常创造了机会。考虑重新发送丢失的网络数据包的情况。也许该数据包实际上并没有丢失,但是只是被延迟了。在这种情况下,重新发送数据包将导致重复的数据包到达对节点;这引入了节点必须处理的新的例外条件。或者,考虑从冗余副本恢复丢失的数据的情况:如果冗余副本也丢失了怎么办?在恢复期间发生的次要异常通常比主要异常更加微妙和复杂。如果通过中止正在进行的操作来处理异常,则必须将此异常作为另一个异常报告给调用方。为了防止无休止的异常级联,开发人员最终必须找到一种在不引入更多异常的情况下处理异常的方法。
语言对异常的支持往往是冗长而笨拙的,这使得异常处理代码难以阅读。例如,考虑以下代码,该代码使用 Java 对对象序列化和反序列化的支持从文件中读取 tweet 的集合:
try (
FileInputStream fileStream = new FileInputStream(fileName);
BufferedInputStream bufferedStream = new BufferedInputStream(fileStream);
ObjectInputStream objectStream = new ObjectInputStream(bufferedStream);
) {
for (int i = 0; i < tweetsPerFile; i++) {
tweets.add((Tweet) objectStream.readObject());
}
}
catch (FileNotFoundException e) {
...
}
catch (ClassNotFoundException e) {
...
}
catch (EOFException e) {
// Not a problem: not all tweet files have full
// set of tweets.
}
catch (IOException e) {
...
}
catch (ClassCastException e) {
...
}只是基本的 try-catch 样板代码比正常情况下的操作代码所占的代码行更多,甚至没有考虑实际处理异常的代码。很难将异常处理代码与普通情况代码相关联:例如,每个异常的生成位置都不明显。另一种方法是将代码分解为许多不同的 try 块。在极端情况下,每行可能产生异常的代码都需要单独的 try 块。这样可以清楚地说明异常发生的位置,但是 try 块本身会破坏代码流,并使代码难以阅读。此外,某些异常处理代码可能最终会在多个 try 块中重复。
确保异常处理代码是否会真正起作用是困难的。某些异常(例如 I/O 错误)在测试环境中不易生成,因此很难测试处理它们的代码。异常在运行的系统中很少发生,因此异常处理代码很少执行。错误可能会长时间未被发现,并且当最终需要异常处理代码时,它很有可能无法正常工作(我最喜欢的一句话是:“未执行的代码无效”) 。最近的一项研究发现,分布式数据密集型系统中超过 90%的灾难性故障是由错误的错误处理引起的 1。当异常处理代码失败时,很难调试该问题,因为它很少发生。
10.2 异常过多
程序员通过定义不必要的异常加剧了与异常处理有关的问题。大多数程序员被教导检测和报告错误很重要。他们通常将其解释为“检测到的错误越多越好”。这导致了一种过度防御的风格,任何看起来有点可疑的东西都会被异常拒绝,从而导致不必要的异常激增,增加了系统的复杂性。
在设计 Tcl 脚本语言时,我自己就犯了这个错误。Tcl 包含一个 unset 命令,可用于删除变量。我定义的 unset 会在变量不存在时抛出错误。当时我认为,如果有人试图删除一个不存在的变量,那么它一定是一个 bug,所以 Tcl 应该报告它。然而,unset 最常见的用途之一是清理以前操作创建的临时状态。通常很难准确预测创建了什么状态,尤其是如果操作中途中止。因此,最简单的方法是删除可能已经创建的所有变量。unset 的定义使得这种情况很尴尬:开发人员最终会在 catch 语句中再使用 try catch 以捕获并忽略 unset 抛出的错误。回顾过去,unset 命令的设计是我在 Tcl 设计中犯下的最大错误之一。
使用异常来避免处理困难的情况是很诱人的:与其想出一种干净的方法来处理它,不如抛出一个异常并将问题转移给调用者。有人可能会争辩说,这种方法可以赋予调用者权力,因为它允许每个调用者以不同的方式处理异常。然而,如果你不知道做什么去处理特殊情况,调用者也很有可能不知道该做什么。在这种情况下生成异常只会将问题传递给其他人,并增加系统的复杂性。
类抛出的异常是其接口的一部分;具有大量异常的类具有复杂的接口,并且比具有较少异常的类浅。异常是接口中特别复杂的元素。它可以在被捕获之前通过多个堆栈级别向上传播,因此它不仅影响方法的调用者,而且还可能影响更高级别的调用者(及其接口)。
抛出异常很容易;处理它们很困难。因此,异常的复杂性来自异常处理代码。减少由异常处理引起的复杂性破坏的最佳方法是减少必须处理异常的位置的数量。本章的其余部分将讨论减少异常处理程序数量的四种技术。
10.3 通过定义规避错误
消除异常处理复杂性的最好方法是设计好您的 API,使其没有异常要处理:这就是 通过定义规避错误。这看似亵渎神灵,但在实践中非常有效。考虑上面讨论的 Tcl unset 命令。当unset被要求删除一个未知变量时,它不应该抛出一个错误,而应该简单地返回而不做任何事情。我应该稍微修改一下 unset 的定义:与其删除一个变量,不如用来确保一个变量不再存在。根据第一个定义,如果变量不存在,则 unset 不能执行其工作,因此生成异常是说的通的。使用第二个定义,对不存在的变量名调用 unset 是很自然的。在这种情况下,它的工作已经完成,因此可以简单地返回。不再有错误需要上报。
10.4 示例:Windows 中的文件删除
文件删除提供了如何通过定义规避错误另一个示例。Windows 操作系统不允许删除文件(如果已在进程中打开文件)。对于开发人员和用户来说,这是不断沮丧的根源。为了删除正在使用的文件,用户必须在系统中搜索以找到已打开文件的进程,然后终止该进程。有时用户放弃并重新启动系统,只是为了删除文件。
Unix 操作系统更优雅地定义了文件删除。在 Unix 中,如果在删除文件时打开了文件,则 Unix 不会立即删除该文件。而是将文件标记为删除,然后删除操作成功返回。该文件名已从其目录中删除,因此其他进程无法打开该旧文件,并且可以创建具有相同名称的新文件,但现有文件数据将保留。已经打开文件的进程可以继续读取和正常写入文件。一旦所有访问进程都关闭了文件,便释放其数据。
Unix 删除文件的方式规避了两种不同的错误。首先,如果文件当前正在使用中,则删除操作不再返回错误;删除成功,该文件最终将被删除。其次,删除正在使用的文件不会使正在使用该文件的进程抛出异常。解决此问题的一种可能方法是立即删除文件并标记所有打开的文件以禁用它们。其他进程读取或写入已删除文件的任何尝试均将失败。但是,此方法将产生需要那些进程处理的新的错误。相反,Unix 允许他们继续正常访问文件。延迟文件删除规避了这个问题。
Unix 允许进程继续读取和写入已损坏的文件可能看起来很奇怪,但是我从未遇到过因此引起严重问题的情况。对于开发人员和用户,Unix 删除文件的设计比 Windows 的设计要容易得多。
10.5 示例:Java 子字符串方法
作为最后一个示例,请考虑 Java String 类及其子字符串方法。给定一个字符串中的两个索引,substring 方法返回从第一个索引给定的字符开始,以第二个索引之前的字符结束的子字符串。但是,如果两个索引中的任何一个超出字符串的范围,substring 方法将抛出 IndexOutOfBoundsException。此异常是不必要的,并且会使此方法的使用复杂化。我经常发现自己处于一个或两个索引可能不在字符串范围内的情况,并且我想提取字符串中与指定范围重叠的所有字符。不幸的是,这要求我检查每个索引并将它们向上舍入为零或向下舍入到字符串的末尾。现在,单行方法调用变成 5-10 行代码。
如果 Java 子字符串方法自动执行此调整,则将更易于使用,因此它实现了以下 API:“返回索引大于或等于 beginIndex 且小于 endIndex 的字符串的字符(如果有)。” 这是一个简单自然的 API,它规避了 IndexOutOfBoundsException 异常。现在,即使一个或两个索引均为负,或者 beginIndex 大于 endIndex,该方法的行为也已明确定义。这种方法简化了方法的 API,同时增加了其功能,因此使方法更深。许多其他语言都采用了这种无错误的方式。例如,Python 对于超出范围的列表切片返回空结果。
当我主张通过设计来规避异常时,人们有时会反驳说抛出异常会捕捉到 bug。如果异常都被设计规避了,那会不会导致古怪的软件出现?也许这就是 Java 开发人员任务 substring 方法应该抛出异常。尽量抛出异常的方式可能会捕获一些错误,但也会增加复杂性,从而导致其他错误。在尽量抛出异常的方式中,开发人员必须编写额外的代码来避免或忽略错误,这增加了出现 bug 的可能性。或者,他们可能会忘记编写额外的代码,在这种情况下,运行时可能会抛出意外的异常。相比之下,通过设计来规避异常将简化 API,并减少必须编写的代码量。
总体而言,减少 bug 最好方法是简化软件。
10.6 屏蔽异常
减少必须处理异常的地方数量的第二种技术是异常屏蔽。使用这种方法,可以在系统的较低级别上检测和处理异常情况,因此,更高级别的软件无需知道该情况。异常屏蔽在分布式系统中尤其常见。例如,在诸如 TCP 的网络传输协议中,由于各种原因(例如损坏和拥塞),可能会丢弃数据包。TCP 在其实现中通过重新发送丢失的数据包来掩盖数据包的丢失,因此所有数据最终都将送达,并且客户端不会察觉到丢失的数据包。
NFS 网络文件系统中出现了一个更具争议性的屏蔽异常的示例。如果 NFS 文件服务器由于任何原因崩溃或无法响应,客户端将一遍又一遍地向服务器发出请求,直到问题最终得到解决。客户端上的低级文件系统代码不会向调用应用程序报告任何异常。执行该操作的进程(及应用程序)只是挂起,直到操作可以成功完成。如果挂起持续的时间超过一小段时间,则 NFS 客户端将在用户控制台上输出“ NFS 服务器 xyzzy 无法响应仍在尝试访问” 之类的消息。
NFS用户经常抱怨他们的应用程序在等待NFS服务器恢复正常运行时挂起。许多人建议 NFS 应该异常终止操作并抛出异常而不是挂起。但是,报告异常会使情况更糟,而不是更好。应用程序在无法访问其文件的情况下也没什么好做的。一种可能性是应用程序重试文件操作,但这仍然会使应用程序挂起,并且在 NFS 层级中一个位置执行重试会比在每个应用程序中的每个文件系统调用处执行重试更容易(编译器应不必为此担心!)。另一种选择是让应用程序中止并将错误返回给调用者。调用者不太可能知道该怎么做,因此他们也将中止,导致用户工作环境崩溃。用户在文件服务器关闭时仍然无法完成任何工作,并且一旦文件服务器恢复工作,他们将不得不重新启动所有应用程序。
因此,最好的替代方法是让 NFS 掩盖错误并挂起应用程序。通过这种方法,应用程序不需要任何代码来处理服务器问题,并且一旦服务器恢复运行,它们就可以无缝恢复。如果用户厌倦了等待,他们总是可以手动中止应用程序。
异常屏蔽并非在所有情况下都有效,但是在它起作用的情况下它是一个强大的工具。它导致了更深的类,因为它减少了类的界面(用户需要注意的异常更少)并以掩盖异常的代码形式添加了功能。异常屏蔽是降低复杂性的一个例子。
10.7 异常聚合
减少与异常相关的复杂性的第三种技术是异常聚合。异常聚合的思想是用一个代码段处理许多异常。与其为多个单独的异常编写不同的处理程序,不如用一个处理程序在一个地方将它们全部处理。
考虑如何处理 Web 服务器中缺少的参数的情况。Web 服务器实现 URL 的集合。服务器收到传入的 URL 时,会将分派到特定的服务方法来处理该 URL 并生成响应。该 URL 包含用于生成响应的各种参数。每个服务方法都将调用一个较低层的方法(将其称为 getParameter)以从 URL 中提取所需的参数。如果 URL 不包含所需的参数,则 getParameter 会抛出异常。
当参加软件设计课程的学生实现这样的服务器时,他们中的许多人将对 getParameter 的每个不同调用包装在单独的异常处理程序中以捕获 NoSuchParameter 异常,如图 10.1 所示。这导致大量的处理程序,所有这些处理程序基本上都执行相同的操作(生成错误响应)。
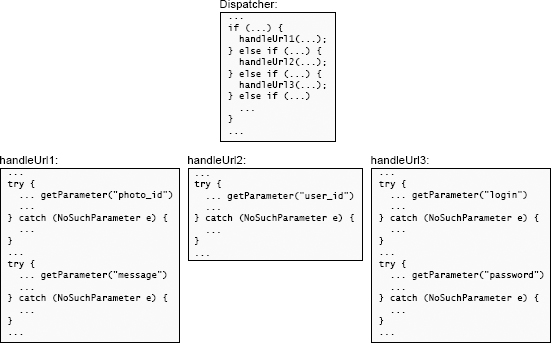
图 10.1:顶部的代码将分派给 Web 服务器中的几种方法之一,每种方法都处理一个特定的 URL。每个方法(底部)都使用传入 HTTP 请求中的参数。在此图中,每个对 getParameter 的调用都有一个单独的异常处理程序。这导致重复的代码。
更好的方法是汇总异常。让它们传播到 Web 服务器的顶级调度方法,而不是在单个服务方法中捕获异常,如图 10.2 所示。此方法中的单个处理程序可以捕获所有异常,并为丢失的参数生成适当的错误响应。
聚合异常的方式可以在 Web 示例中更进一步。处理网页时,除了缺少参数外,还有许多其他错误;例如,参数可能没有正确的类型(服务方法期望的参数时整数,但值为“ xyz”),或者用户可能无权执行所请求的操作。在每种情况下,错误都应导致错误响应。错误仅在响应中包含的错误消息中有所不同(“ URL 中不存在参数’quantity’” 或 “‘quantity’参数的值 ‘xyz’ 不正确;必须为正整数”)。因此,所有导致错误响应的条件都可以使用单个顶级异常处理程序进行处理。错误消息可以在引发异常时生成,并作为变量包含在异常记录中。例如,getParameter 将生成“ URL 中不存在的参数’quantity’”消息。顶级处理程序从异常中提取消息,并将其合并到错误响应中。

图 10.2:此代码在功能上等效于图 10.1,但是异常处理已聚合:分派器中的单个异常处理程序从所有特定于 URL 的方法中捕获所有 NoSuchParameter 异常。
从封装和信息隐藏的角度来看,上一段中描述的异常聚合具有良好的属性。顶级异常处理程序封装了有关如何生成错误响应的知识,但对特定错误一无所知。它仅使用异常中提供的错误消息。getParameter 方法封装了有关如何从 URL 提取参数的知识,并且还知道如何以人类可读的形式描述提取的错误。这两个信息密切相关,因此将它们放在同一位置是说得通的。但是,getParameter 对 HTTP 错误响应的语法一无所知。随着向 Web 服务器中添加了新功能,可能会创建具有类似 getParameter 有自己的异常的新方法。如果新方法抛出异常的方式和 getParameter 一样(继承自同一基类并且包含错误信息),现存系统不用做任何更改就可以集成新的方法:顶级异常处理程序会自动为新方法生成相应的错误响应。
此示例说明了用于异常处理的通用设计模式。如果系统处理一系列请求,则定义一个异常以中止当前请求,清除系统状态并继续下一个请求非常有用。异常被捕获在系统请求处理循环顶部附近的单个位置。在处理中止请求的任何时候都可以抛出异常。可以为不同的条件定义异常的不同子类。应该将这种类型的异常与对整个系统致命的异常区分开来。
如果异常在被处理之前在堆栈中传播到了多个级别,则异常集合最有效。这允许在同一个地方处理来自更多方法的更多异常。这与异常屏蔽相反:异常屏蔽通常在异常被低级代码处理的情况下效果最好。对于异常屏蔽,低级方法通常是被许多其他方法使用的库方法,因此,允许传播异常会增加需要处理该异常的位置数量。异常屏蔽和异常聚合的相似之处在于,这两种方式都将异常处理程序置于可以捕获最多异常的位置,从而消除了许多本来需要创建的异常处理程序。
异常聚合的另一个例子是 RAMCloud 存储系统崩溃恢复。RAMCloud 系统由一组存储服务器组成,这些存储服务器保留每个对象的多个副本,因此系统可以从各种故障中恢复。例如,如果服务器崩溃并丢失其所有数据,RAMCloud 会使用存储在其他服务器上的副本来重建丢失的数据。错误也可能在较小的范围内发生。例如,服务器可能发现单个对象已损坏。
对于每种不同类型的错误,RAMCloud 没有单独的恢复机制。相反,RAMCloud 将许多较小的错误“提升”为较大的错误。原则上,RAMCloud 可以通过从备份副本中恢复一个损坏的对象来处理这个损坏的对象。然而,它并不这样做。相反,如果它发现一个损坏的对象,它会使包含该对象的服务器崩溃。RAMCloud 使用这种方法是因为崩溃恢复非常复杂,而且这种方法最小化了必须创建的不同恢复机制的数量。为崩溃的服务器创建恢复机制是不可避免的,因此 RAMCloud 对其他类型的恢复也使用相同的机制。这减少了必须编写的代码量,而且这还意味着服务器崩溃恢复将更频繁地被调用。因此,恢复中的 bug 更有可能被发现和修复。
将损坏的对象升级为服务器崩溃的一个缺点是,它大大增加了恢复成本。这在 RAMCloud 中不是问题,因为对象损坏非常罕见。但是,错误升级对于经常发生的错误可能没有意义。举一个例子,在服务器的任何网络数据包丢失时使服务器崩溃是不切实际的。
考虑异常聚合的一种方法是,它用可以处理多种情况的单个通用机制替换了几种针对特定情况而量身定制的特殊用途的机制。这再次说明了通用机制的好处。
10.8 让程序崩溃?
减少与异常处理相关的复杂性的第四种技术是使应用程序崩溃。在大多数应用程序中,有些错误是不值去处理的。通常,这些错误很难或不可能处理,而且很少发生。针对这些错误的最简单的操作是打印诊断信息,然后中止应用程序。
一个示例是在存储分配期间发生的“内存不足”错误。考虑一下 C 语言中的 malloc 函数,如果它无法分配所需的内存块,则该函数将返回 NULL。这是一个不合适的行为,因为它假定 malloc 的每个调用者都将检查返回值并在没有内存的情况下采取适当的措施。应用程序包含许多对 malloc 的调用,因此在每次调用后检查结果将增加相当大的复杂性。如果程序员忘记了检查(这很有可能),那么如果内存用完,应用程序将取消引用空指针,从而导致崩溃,从而掩盖了实际问题。
此外,当应用程序发现内存已用完时,它也没什好做的了。原则上,应用程序可以寻找不需要的内存以释放它,但是,如果应用程序有不需要的内存,它可能已经释放了它,这将首先防止内存不足的错误。当今的系统具有如此大的内存,以至于内存几乎永远不会耗尽。如果是这样,通常表明应用程序中存在 bug。因此,尝试处理内存不足错误几乎没有道理。这会带来太多的复杂性,而带来的收益却太少。
更好的方法是定义一个新的 ckalloc 方法,该方法调用 malloc,检查结果,在内存耗尽时中止应用程序并输出错误消息。该应用程序从不直接调用 malloc。它总是调用 ckalloc。
在较新的语言(例如 C++ 和 Java)中,如果内存耗尽,则 new 运算符将引发异常。捕获此异常没有什么意义,因为异常处理程序很有可能还会尝试分配内存,这也会失败。动态分配的内存是任何现代应用程序中的基本元素,如果内存耗尽,则继续应用程序是没有意义的。最好在检测到错误后立即崩溃。
还有许多其他错误示例,当这些错误出现时使应用程序崩溃是说得通的。对于大多数程序,如果在读取或写入打开的文件时发生 I/O 错误(例如磁盘硬错误),或者无法打开网络套接字,则应用程序没有什么办法从在错误中恢复,因此中止程序并输出清晰的错误信息是明智之举。这些错误很少发生,因此它们不太可能影响应用程序的整体可用性。如果应用程序遇到内部错误(如数据结构不一致),则中止程序并输出清晰的错误信息也是合适的。这样的情况可能表明程序中存在 bug。
当特定错误出现时应用程序崩溃是否可以接受取决于应用程序。对于复制的存储系统,不适合因 I/O 错误而中止。相反,系统必须使用复制的数据来恢复丢失的任何信息。恢复机制将给程序增加相当大的复杂性,但是恢复丢失的数据是系统为用户提供的价值的重要组成部分。
10.9 通过设计规避特殊情况
通过定义规避错误是说得通的,出于同样的原因,通过设计规避特殊情况也是说得通的。特殊情况可能导致代码中混入 if 语句,这使代码难以理解并导致错误。因此,应尽可能消除特殊情况。做到这一点的最好方法是以一种无需任何额外代码就能自动处理特殊情况的方式来设计正常情况。
在第 6 章中描述的文本编辑器项目中,学生必须实现一种选择文本以及复制或删除所选内容的机制。大多数学生在他们的选择实现中引入了状态变量,以表明选择是否存在。他们之所以选择这种方法,是因为有时屏幕上看不到任何选择,因此在实现中似乎很自然地代表了这一概念。但是,这种方法导致了大量的检查,以检测“没有选择”的情况,并专门处理它。
通过消除“不选择”的特殊情况,可以简化选择处理代码,从而使选择始终存在。当屏幕上没有可见的选择时,可以在内部用空的选择表示,其开始和结束位置相同。使用这种方法,可以编写选择管理代码,而无需对“不选择”进行任何检查。复制所选内容时,如果所选内容为空,则将在新位置插入 0 字节(如果正确实现,则在特殊情况下无需检查 0 字节)。同样,应该有可能设计用于删除选择的代码,以便无需任何特殊情况检查就可以处理空情况。考虑选择一整行的情况。要删除选择,提取选择之前的行的一部分,并将其与选择之后的行的部分连接起来以形成新行。如果选择为空,则此方法将重新生成原始行。
此示例还说明了第 7 章中的“不同的层,不同的抽象”概念。“无选择”的概念在用户对应用程序界面的看法方面很有意义,但这并不意味着必须明确在应用程序内部表示它。选择总是存在的,但有时是空的,因此是不可见的,这样可以简化实现。
10.10 做过头了
通过定义规避错误或将其屏蔽在模块内部,仅在模块外部不需要异常信息时才有意义。对于本章中的示例,例如 Tcl unset 命令和 Java 子字符串方法,都是如此。在极少数情况下,调用者关心异常检测到的特殊情况,还有其他方法可以获取此信息。
但是,有时候会做的过头。在用于网络通信的模块中,一个学生团队掩盖了所有网络异常:如果发生网络错误,则模块将其捕获,丢弃并继续进行,就好像没有问题一样。这意味着使用该模块的应用程序无法确定消息是否丢失或节点服务器是否发生故障;没有这些信息,就不可能构建健壮的应用程序。在这种情况下,模块必须公开异常,即使它们增加了模块接口的复杂性。
异常与软件设计中的许多其他领域一样,您必须确定哪些是重要的,哪些是不重要的。不重要的事物应该被隐藏起来,它们越多越好。但是,当某件事很重要时,必须将其暴露出来。
10.11 结论
任何形式的特殊情况都使代码更难以理解,并增加了发生 bug 的可能性。本章重点讨论异常,异常是特殊情况代码的最重要来源之一,并讨论了如何减少必须处理异常的地方的数量。做到这一点的最佳方法是重新定义语义以消除错误条件。对于无法通过设计规避的异常,您应该寻找机会将它们在底层屏蔽,以免影响有限,或者将多个特殊情况的处理程序聚合到一个更通用的处理程序中。总之,这些技术会对整个系统的复杂性产生重大影响。
1 丁元等 等人,“简单的测试可以防止最关键的故障:对分布式数据密集型系统中的生产故障的分析”,2014 USENIX 操作系统设计和实施大会。